平常小程序写的多一些,简单总结一下原理。但因为小程序也没开源,只能参考相关文档以及开发者工具慢慢理解了。
理解小程序原理的突破口就是开发者工具了,开发者工具是基于 NW.js,一个基于 Chromium 和 node.js 的应用运行时。同时暴漏了 debug 的入口。
点开后就是一个新的 devTools 的窗口,这里我们可以找到预览界面的 dom。
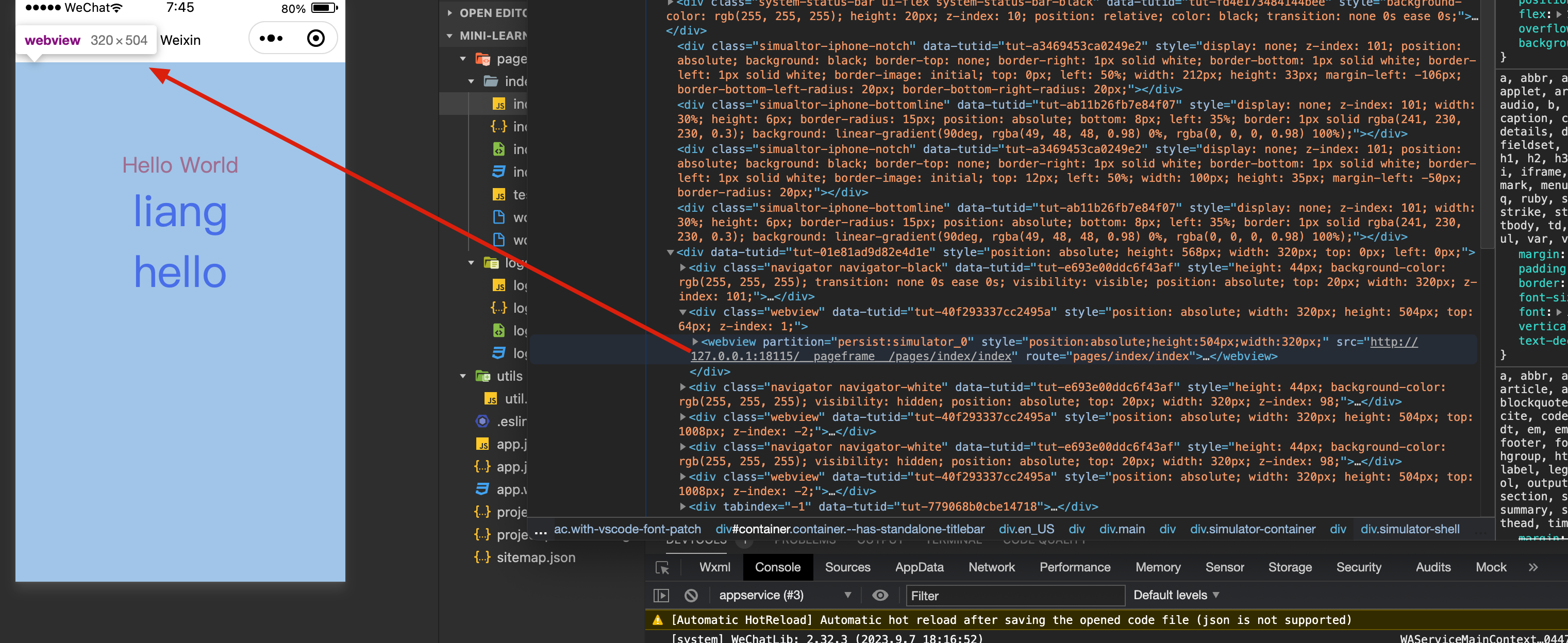
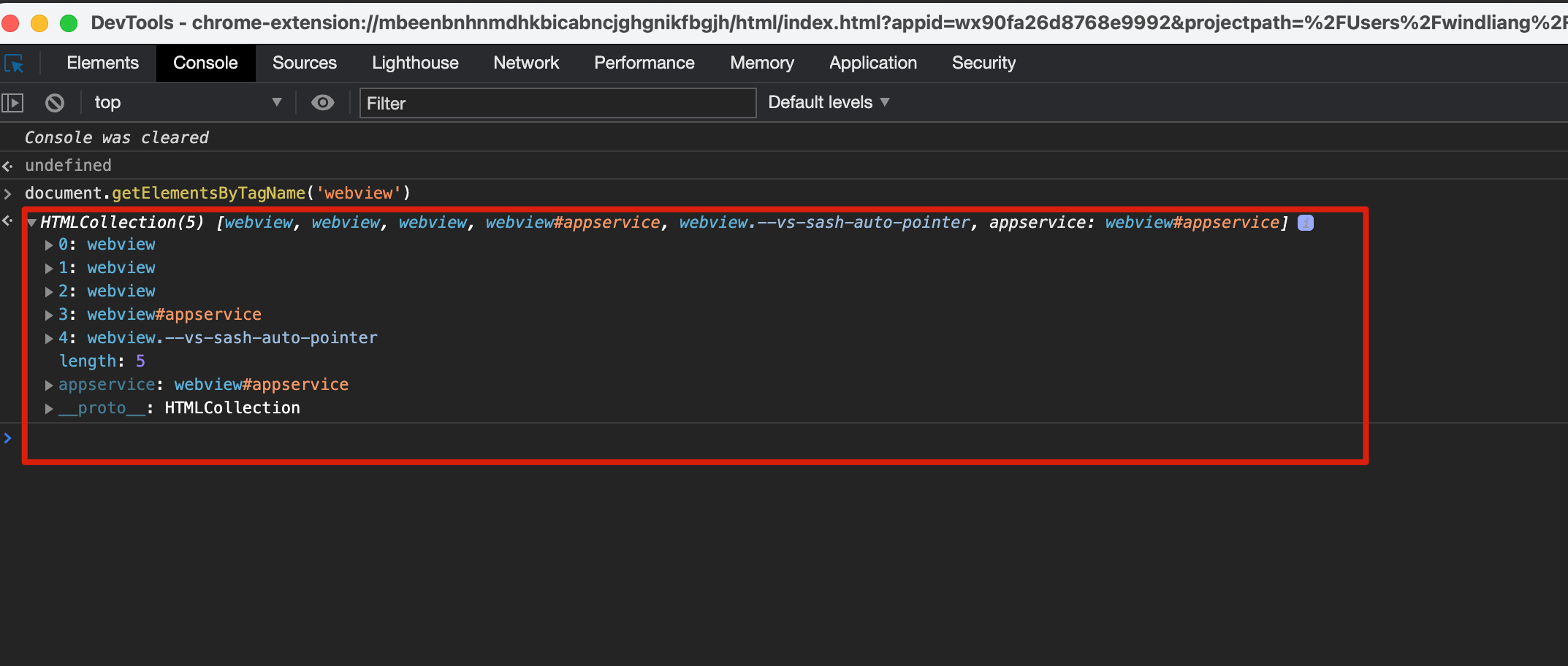
小程序界面是一个独立的 webview,也就是常说的视图层,可以在命令行执行 document.getElementsByTagName('webview') ,可以看到很多 webview。
我这边第 0 个就是 pages/index/index 的视图层,再通过 document.getElementsByTagName('webview')[0].showDevTools(true) 命令单独打开这个 webview 。
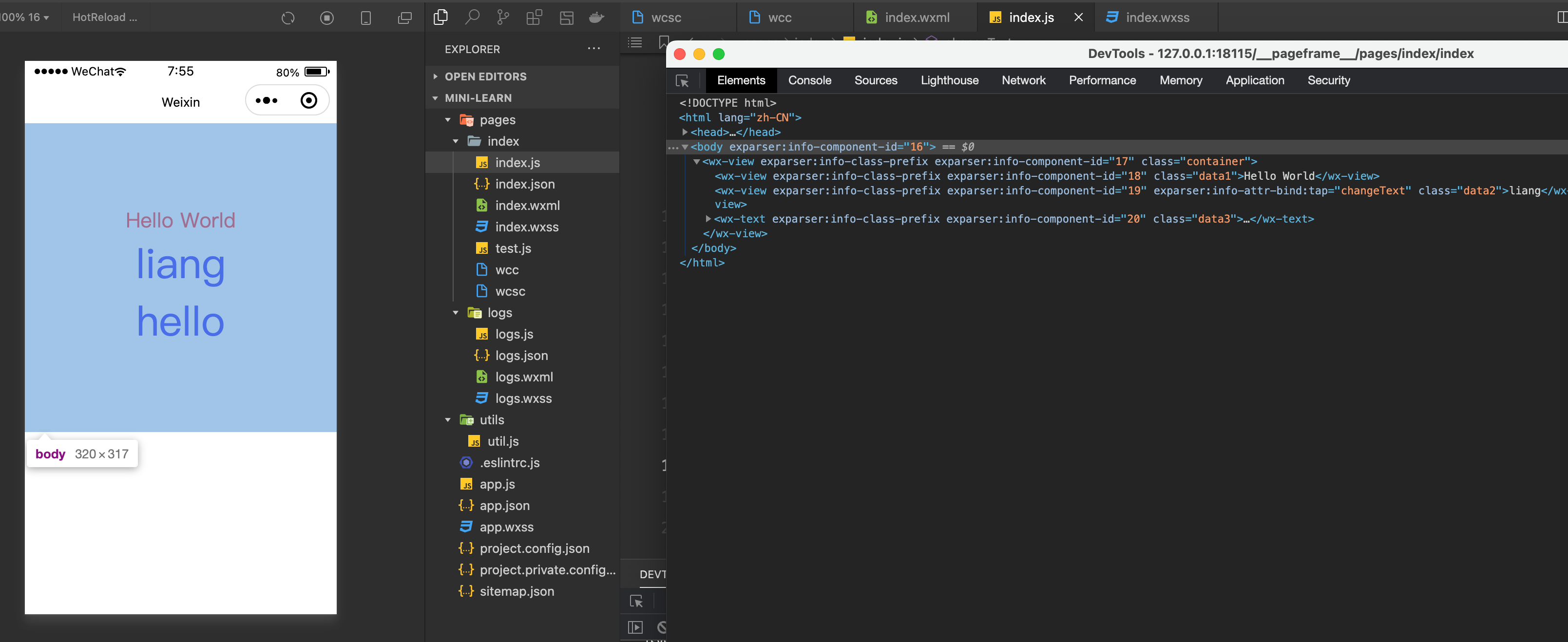
熟悉的感觉回来了,其实就是普通的 html/css ,小程序的原理的突破口也就在这里了。
这篇文章简单看一下页面的 dom 是怎么来的,也就是 wxml 做了什么事情。
源代码:
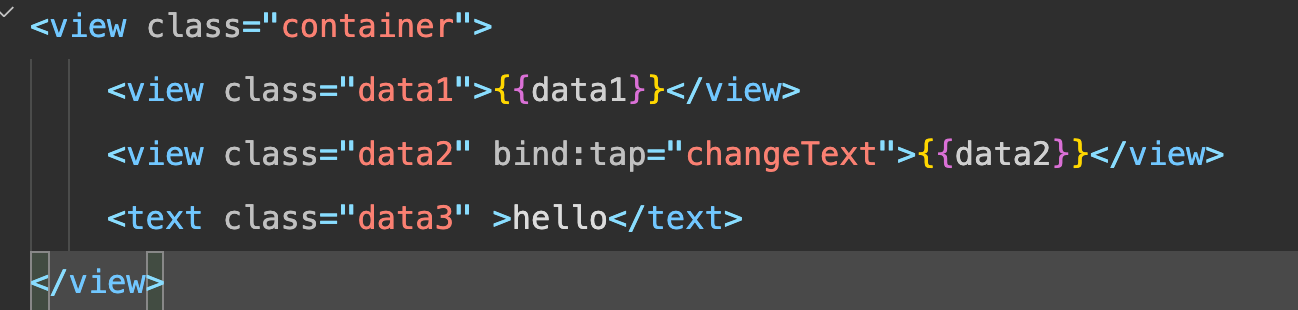
渲染出来的代码:

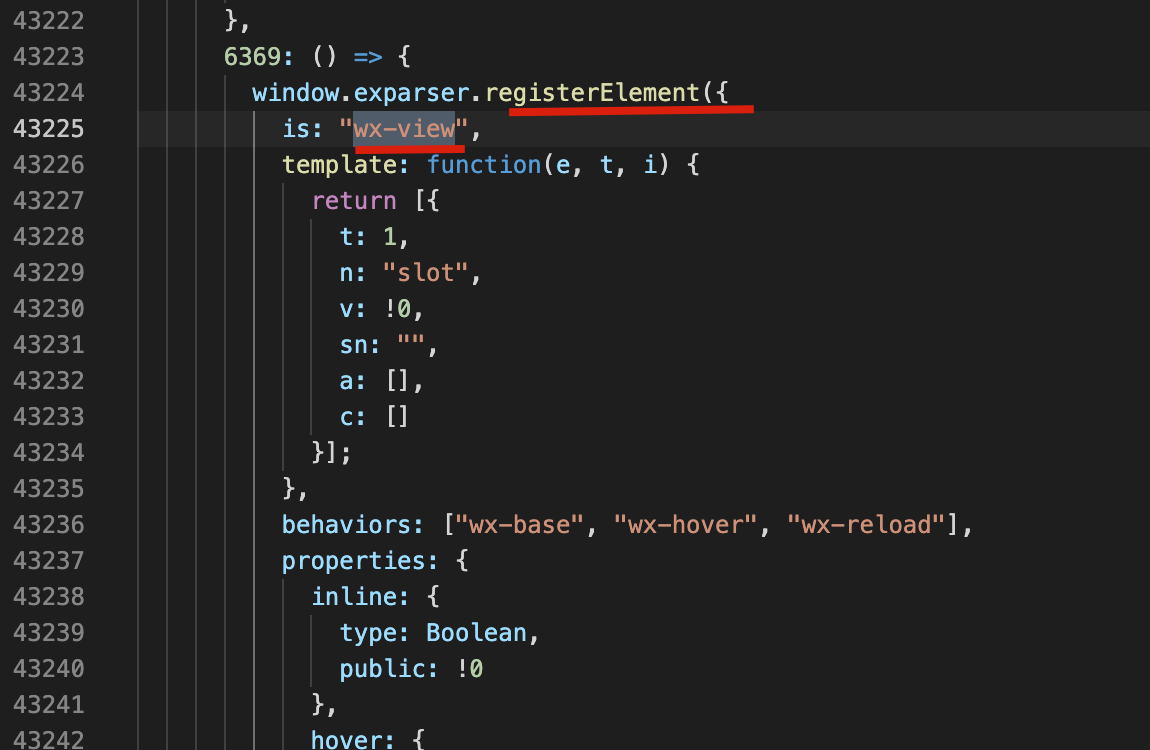
view 变成了 wx-view ,text 变成了 wx-text ,并且里边加了 <span>。两个关键信息,wx-xxx 标签以及 exparser 。
自定义标签
html 是支持我们直接写自定义名字的标签的,并且在上边设置 class 也会直接生效。

区别在于自己写的标签没有一些预制的属性,比如 div 的 display: block 。

如果我们给 wx-view 也加个 display: block ,那表现上它和 div 也就一致了。
微信已经帮我们把自定义标签的属性提前内置了。

至于为什么要把我们写的 view 转成 wx-view ,因为自定义元素中规定必须用 - 连接。
“自定义元素的名字必须包含一个破折号(
-)所以<x-tags>、<my-element>和<my-awesome-app>都是正确的名字,而<tabs>和<foo_bar>是不正确的。这样的限制使得 HTML 解析器可以分辨那些是标准元素,哪些是自定义元素。”
有 - 可以保证一定的兼容性,并且也可以和浏览器自带的元素有一定的区分。
Exparser
简单讲,就是一个仿照 Web Components 的组件系统,它会维护标签的属性、事件,提供 registerElement 方法用于注册自定义组件,提供 createElement 来渲染组件,对于自定义组件会采用 Shadow DOM 的技术。
Exparser 的相关代码在哪里呢?这就是微信传说中的基础库里了,在渲染层引入的是 WAWebview.js 。
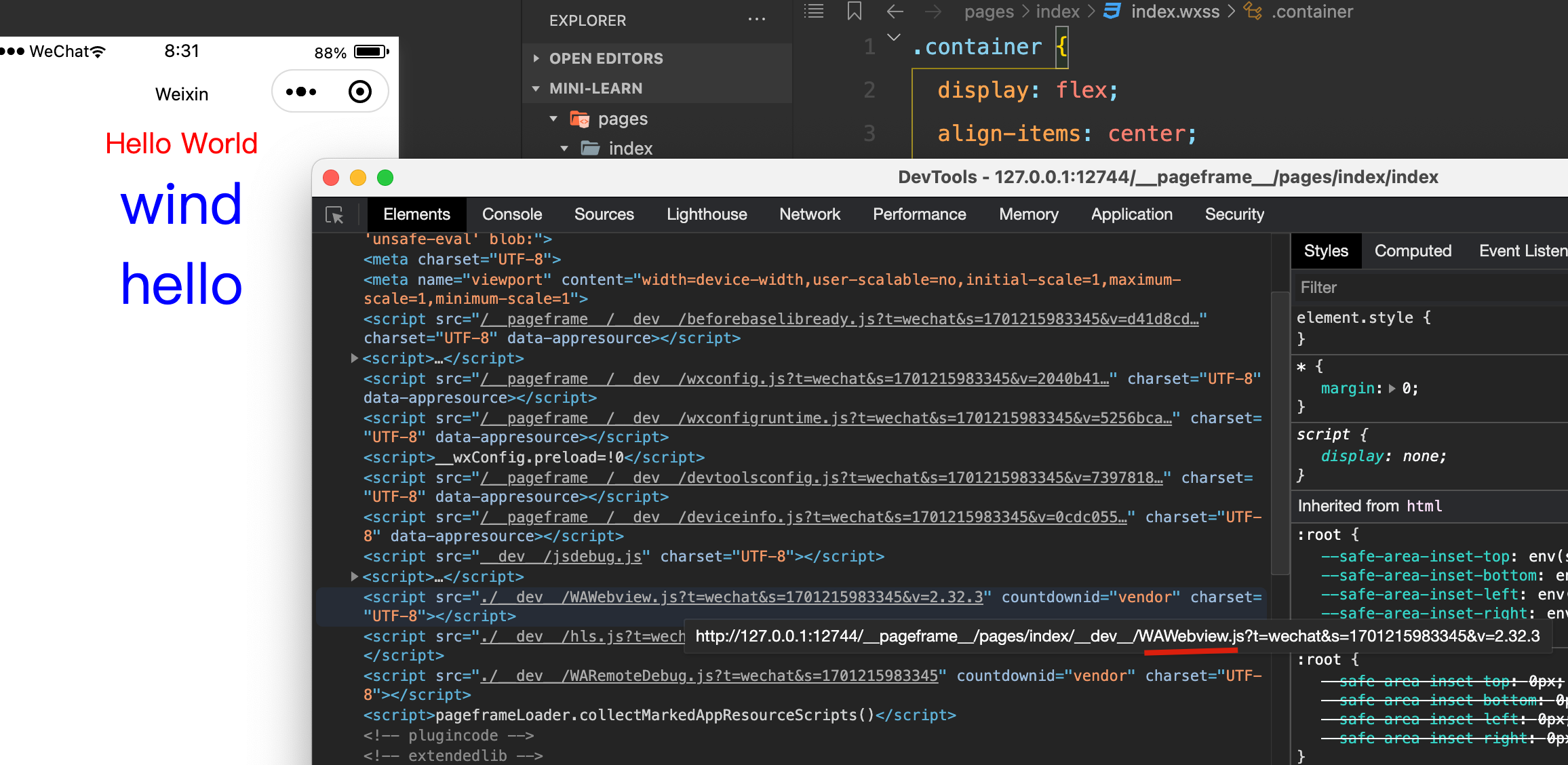
可以右键打开这个文件,复制出来格式化一下:

由于文件比较大,用 VSCode 直接格式化可能会很卡,可以写个脚本来格式化。
1 | // chatGPT 生成 |
然后在命令行执行 node format.js ./WAWebview.js ,接下来就看到格式化的代码了:
是 2.32.3 版本,目前微信已经更到 3.x.x 了,新增了渲染引擎 Skyline,为了简单些这次就先看 2.x 的版本了。
总共有 14 万行

接下来通过搜索、折行,找一下 Exparser 的部分,因为都是压缩过的代码,逐行理解肯定不现实,就找几个关键点看一下:
提供了注册组件的方法 registerElement 。
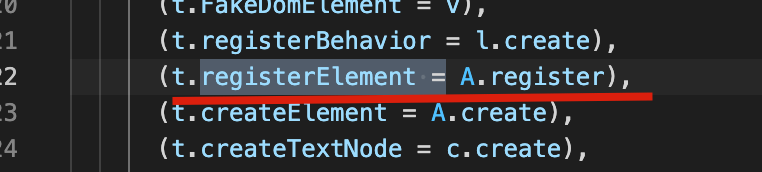

提前注册了内置的组件:
wx-view:
wx-text :
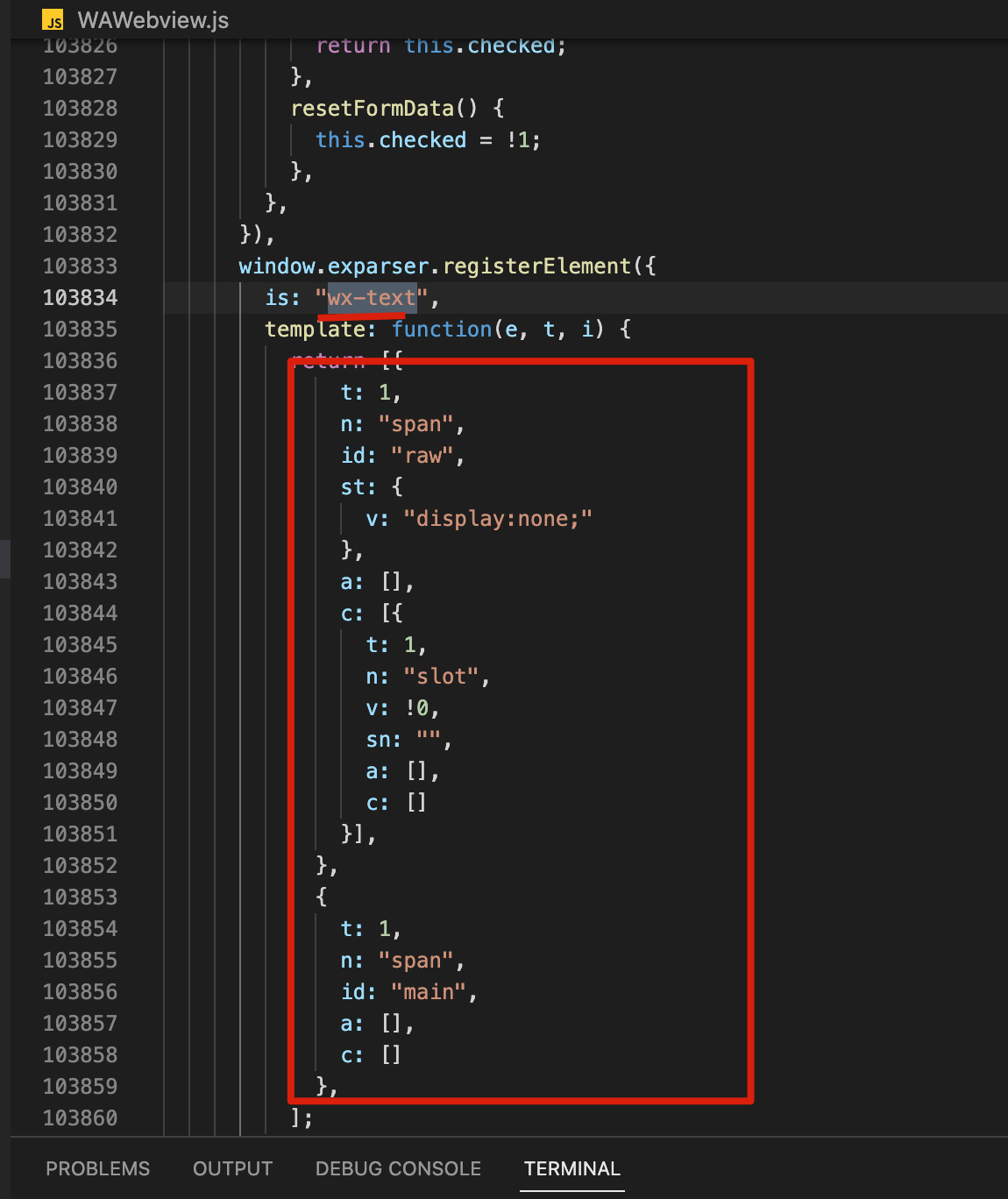
可以看到上边最终转成了 span 标签,和我们开发者工具看到的也是一致的:

提供了 createElement 方法,将注册的组件生成为最终的 dom 。

最终会调用 document 来创建 dom 。
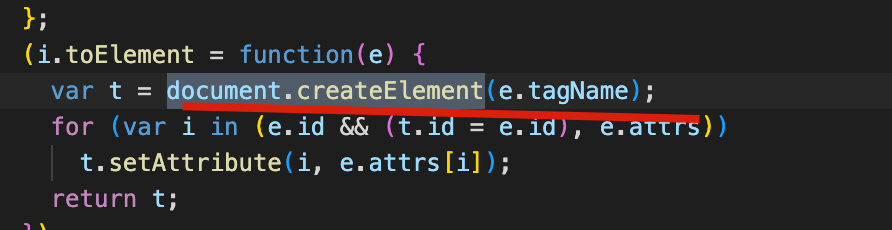
生成流程
再回到加载的 dom 看一下 wxml 转换成了什么:

右键打开这个文件:
定义了 $gw 这个函数,接收 path 参数。
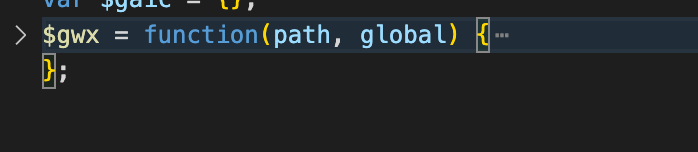
返回一个函数:

内部有我们 wxml 的变量:

对应于原文件:
看一下调用这个函数的地方:
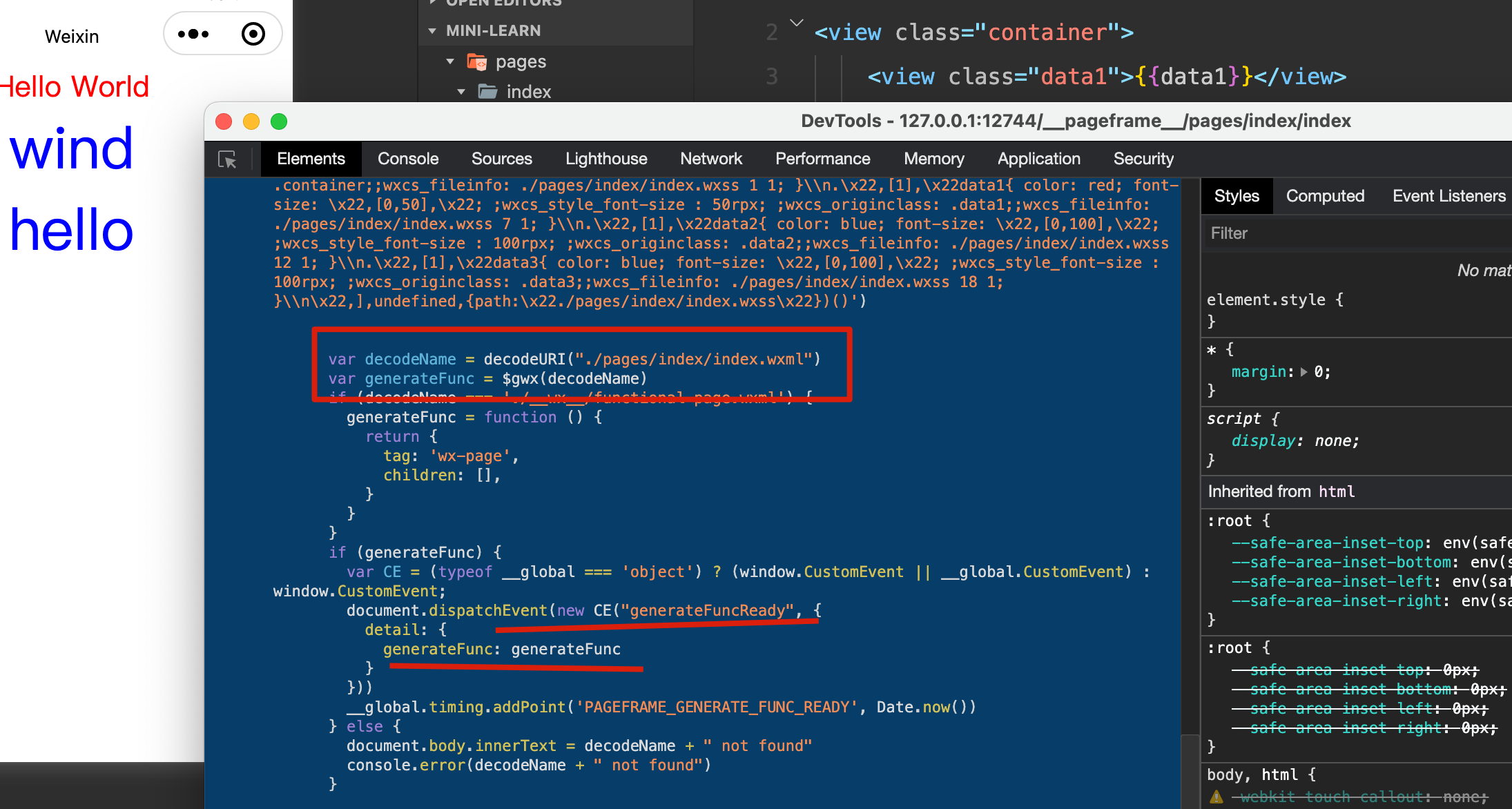
传入当前页面路径将生成的函数赋值给了 generateFunc ,接着用 document.dispatchEvent 触发事件 generateFuncReady,并且将 generateFunc 传入。
我们在控制台手动执行一下 generateFunc ,看下返回值:
可以看到 3 个子元素:
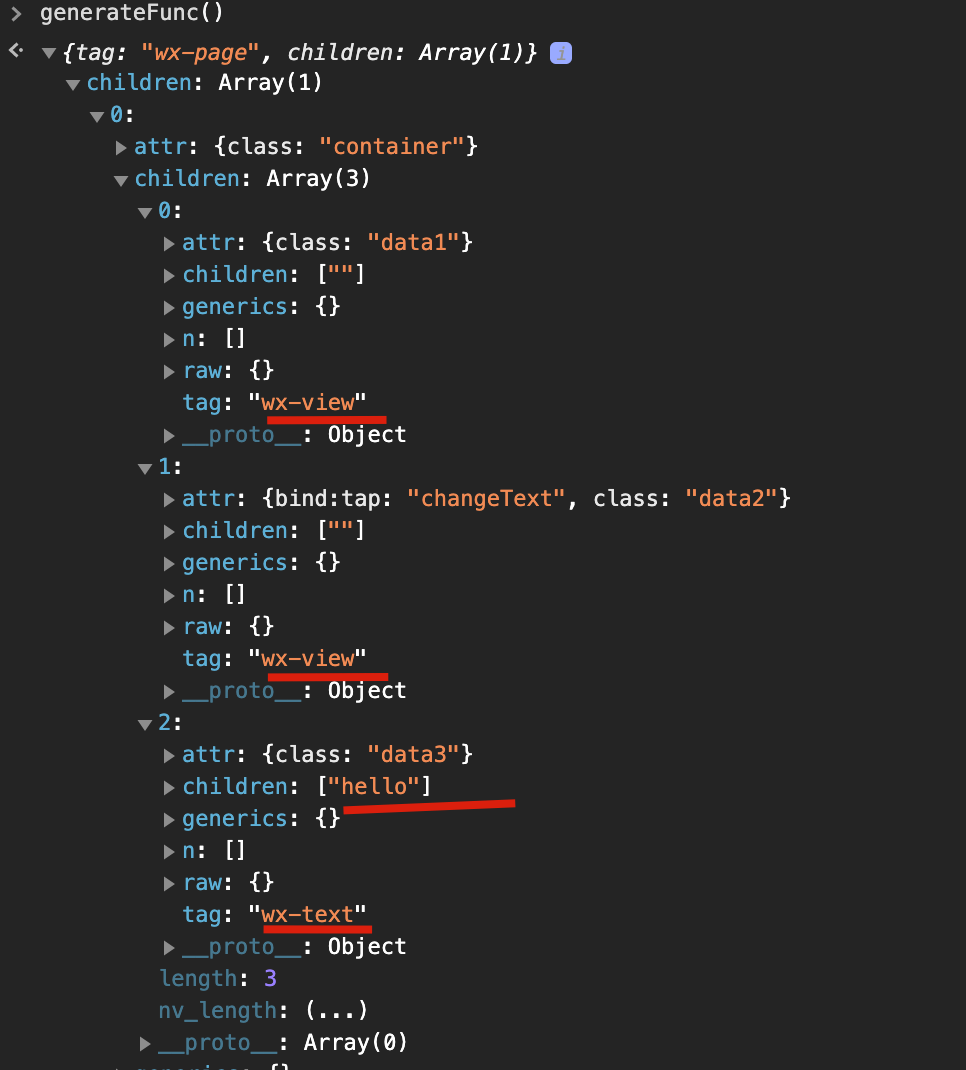
但因为前两个的值是在逻辑层 data 中,因为我们没有传递,所以上边前两个子元素 children 都是空字符串
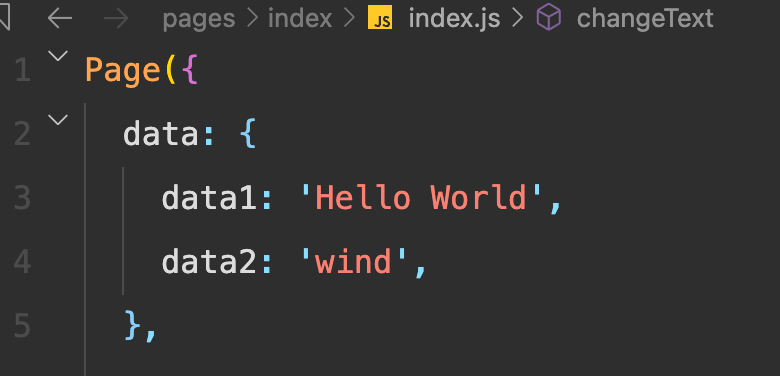
这个 data 需要在调用 generateFunc 的时候传入:
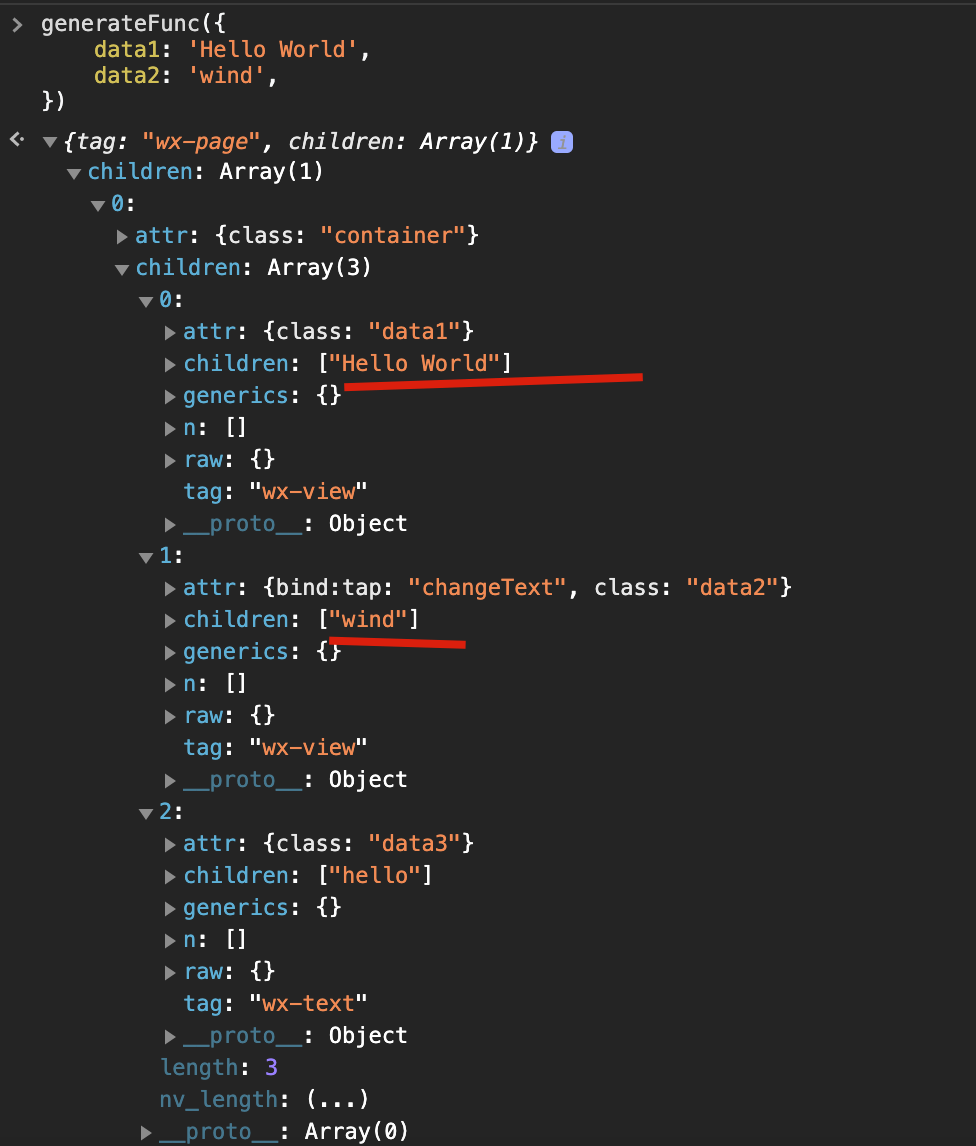
现在就正常返回了标签的结构,接着渲染层内部就会利用它生成虚拟 dom ,再利用 Exparser 生成最终的 dom 元素了。
大概是下边的流程(下边的代码是最早期的基础库,目前的版本已经不是下边的结构了,目前先按下边的流程理解,后边再理清当前基础库的逻辑):
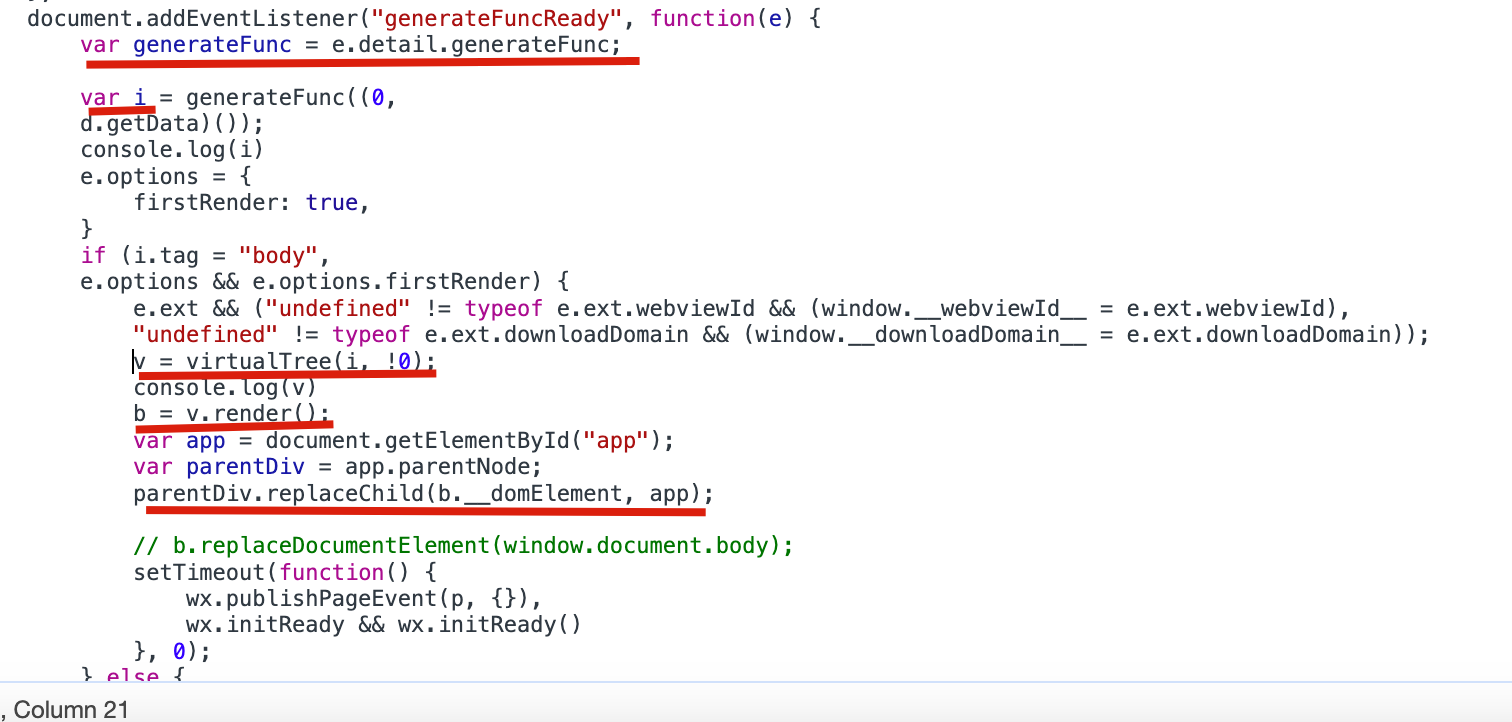
调用 virtualTree 将 generateFunc 返回的结构变为虚拟 dom ,接着调用 render ,render 内部就是调用前边介绍的 Exparser 的 createElement 方法生成真正的 dom ,最后通过 replaceChild 挂载到页面上。
当然 generateFunc 需要的 data 数据需要等待逻辑层传过来,后边的文章再介绍通信机制。
编译
剩下最后一个问题,wxml.js 是哪里来的?
和 wxss 一样,是微信提前编译生成的。编译工具可以在微信开发者工具目录搜索 wcc ,Library 是个隐藏目录。
我们把这个 wcc 文件拷贝到 index.wxml 的所在目录,然后将我们的 index.wxml 手动编译一下:
1 | ./wcc -js ./index.wxml >> wxml.js |
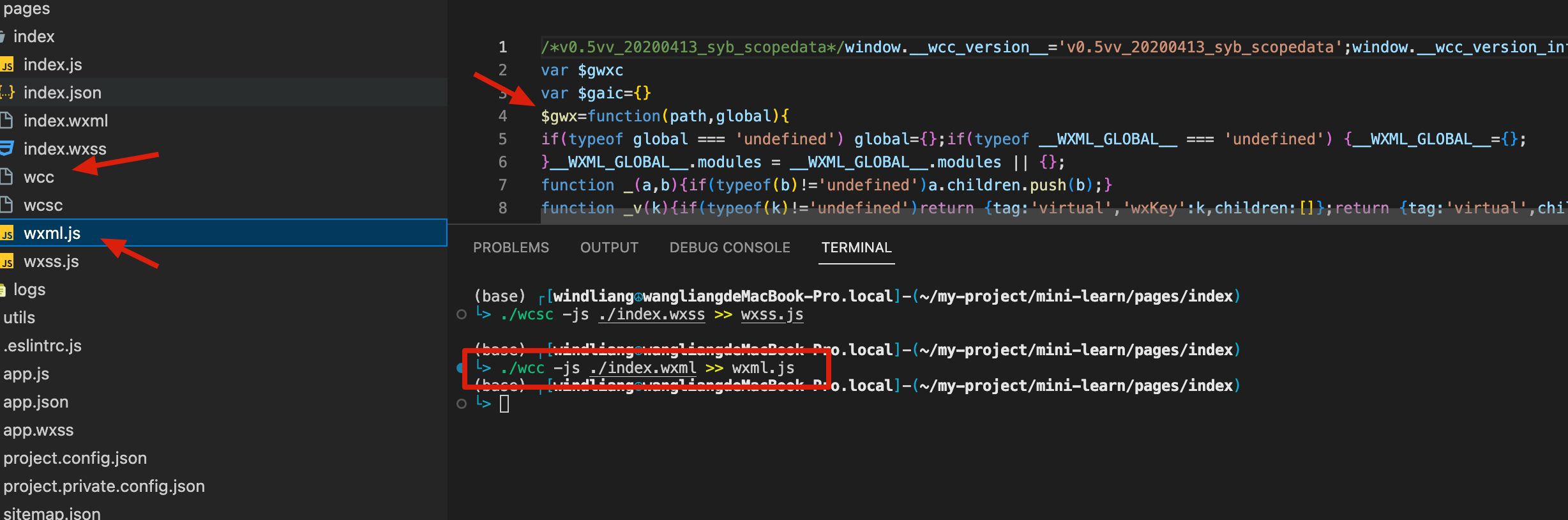
可以看到 $gw 函数就生成了。
总
大概过程就是上边了,先提前编译出了 $gw 函数,会返回一个函数,可以把 wxml 实例为一个 dom 的标签结构。传入当前页面的路径执行该函数生成 generateFunc 函数,将函数传给视图层。
视图层拿到逻辑层的数据后将 generateFunc 函数返回的 dom 结构生成虚拟 dom ,通过 Exparser 执行 render 生成最终的 dom 挂载到页面。
至于拿到逻辑层的数据的时机,相互通信的逻辑就放到后边的文章了,看着混淆的代码,头大。
历史文章:
