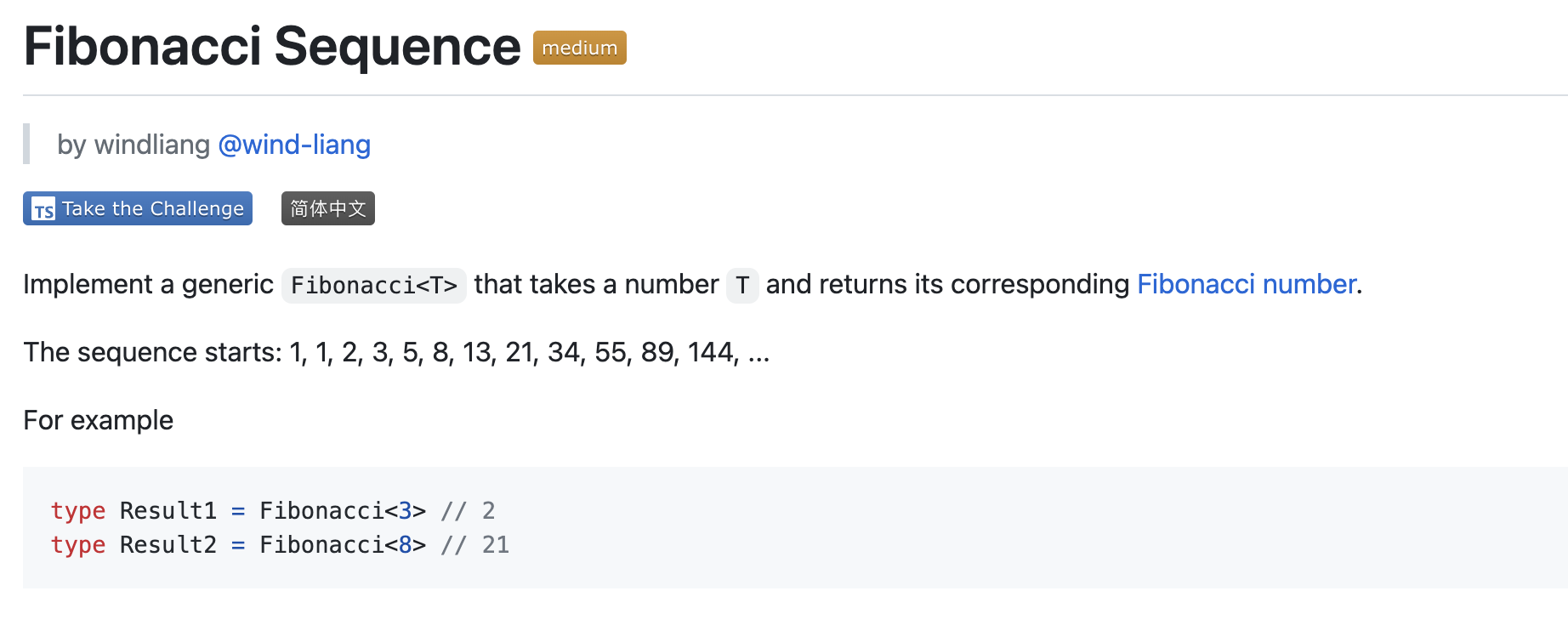
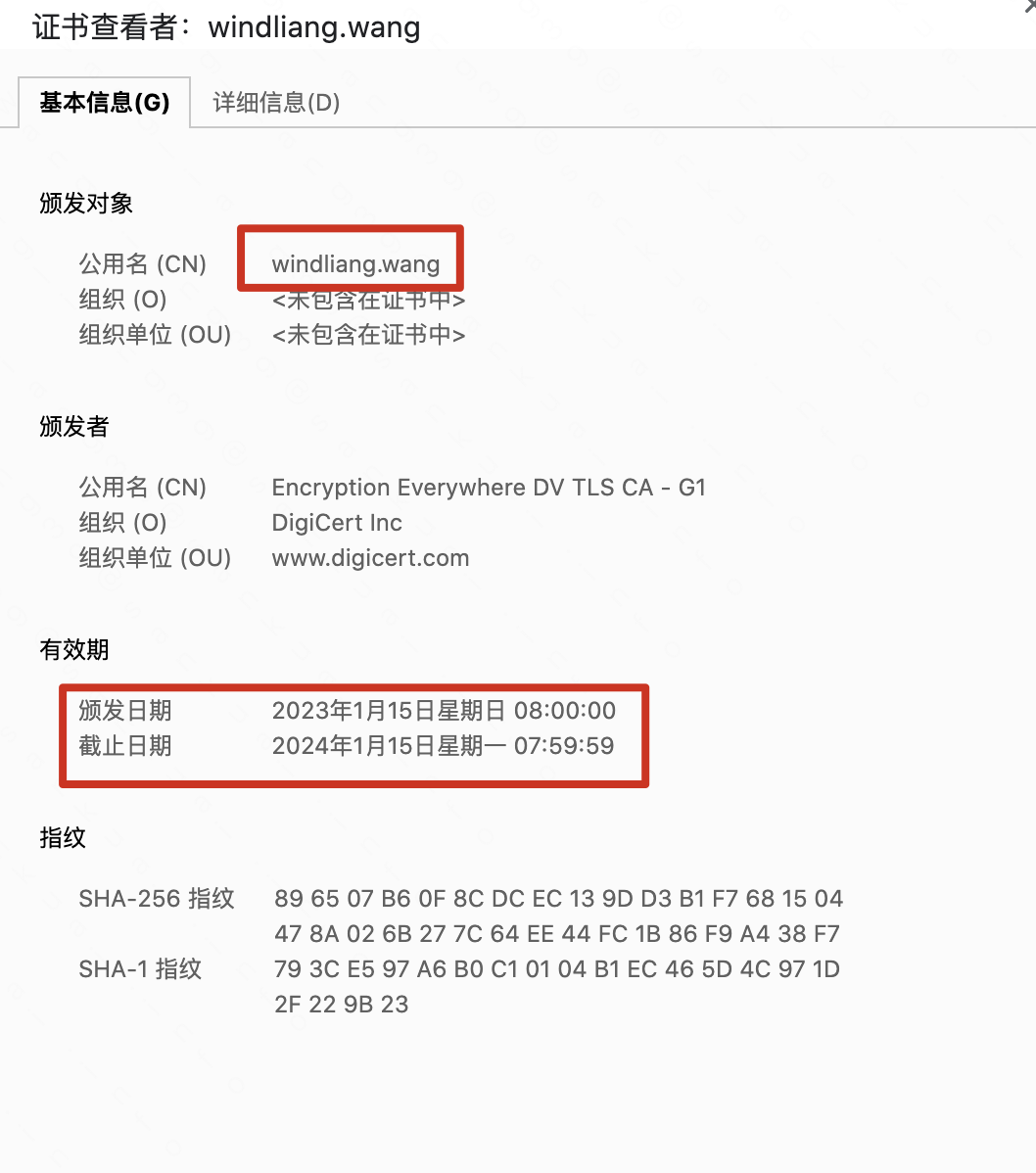
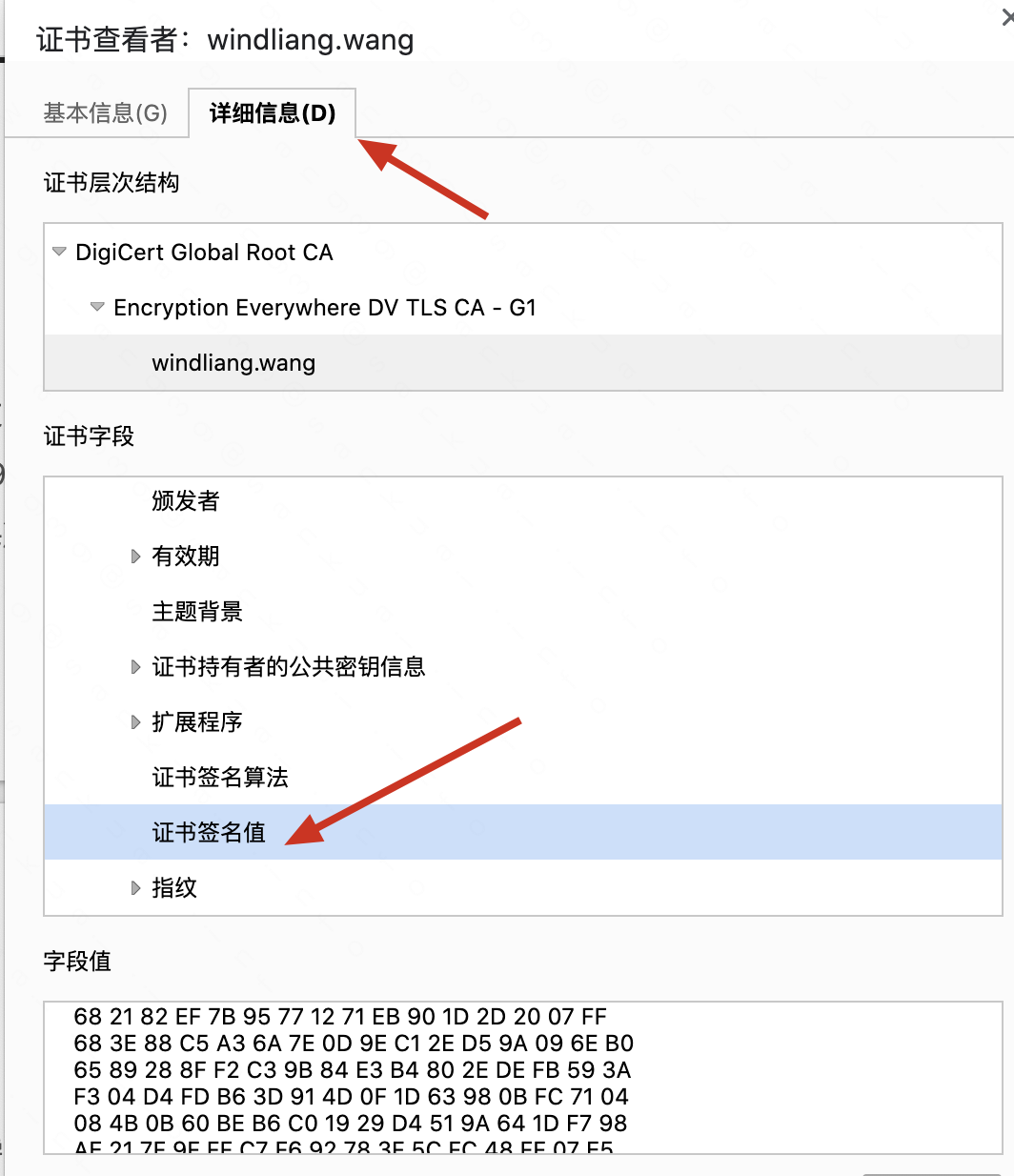
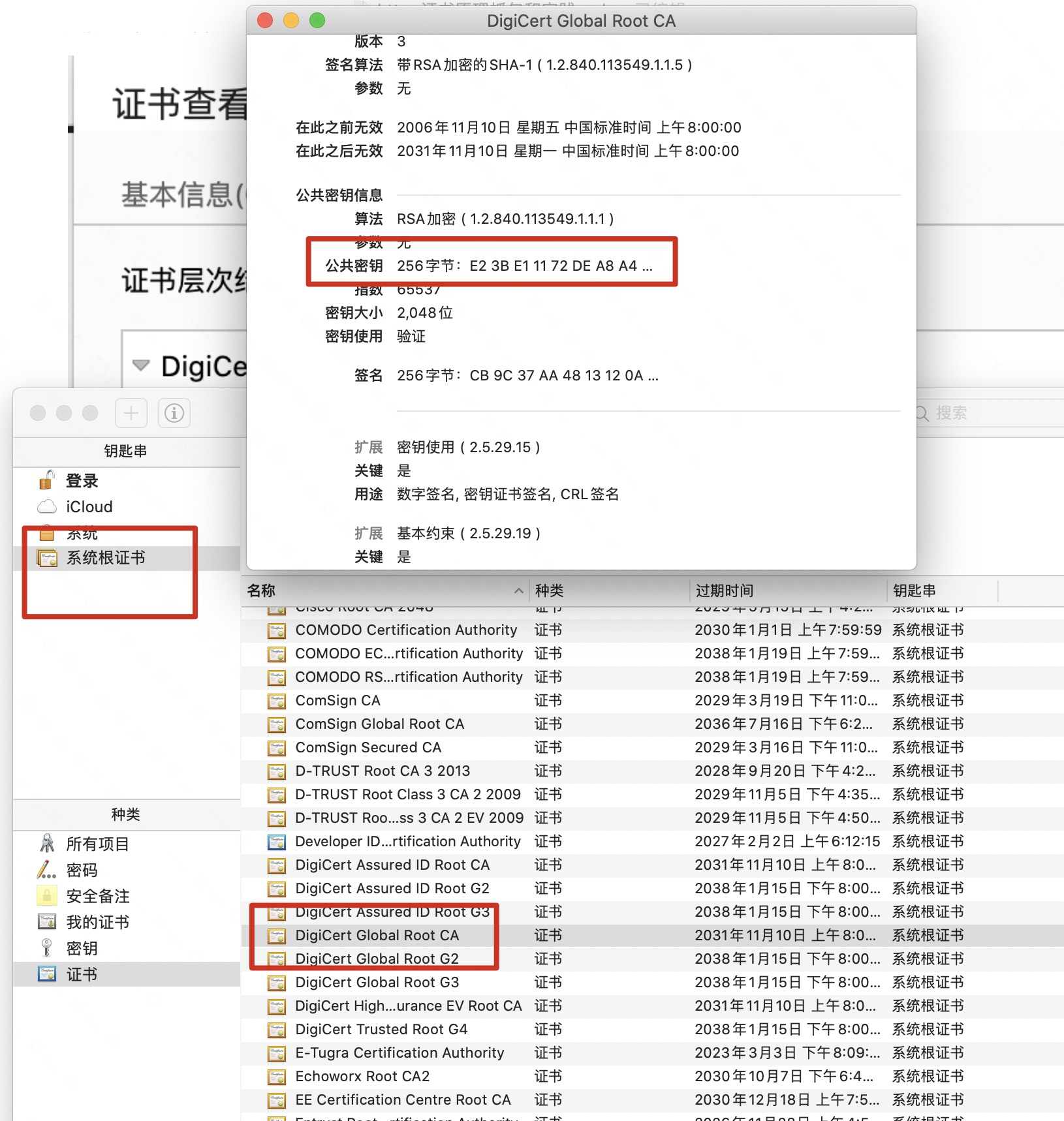
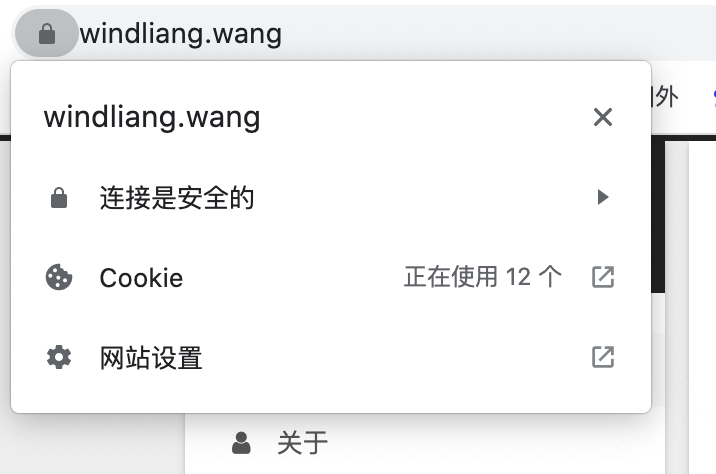
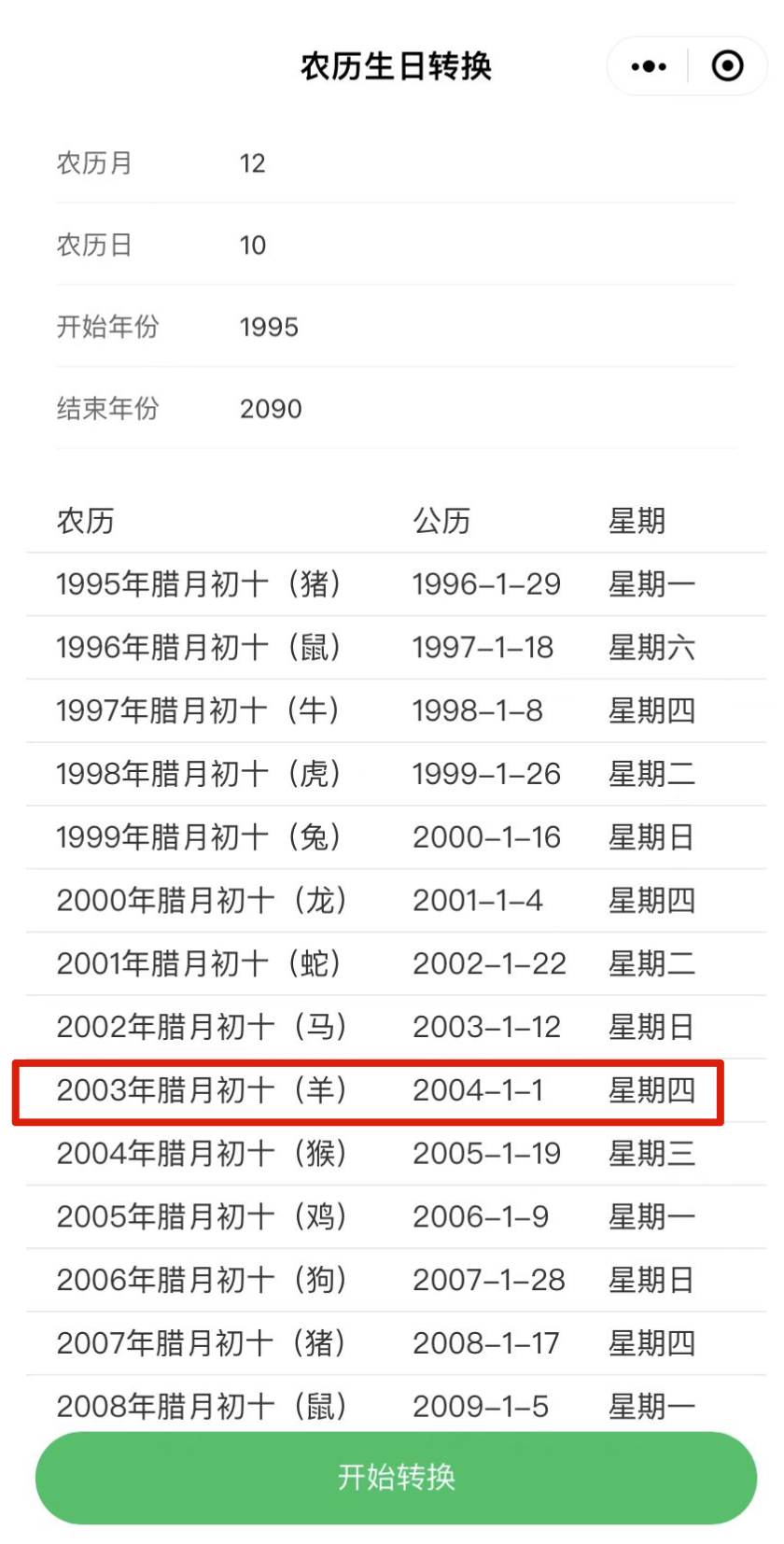
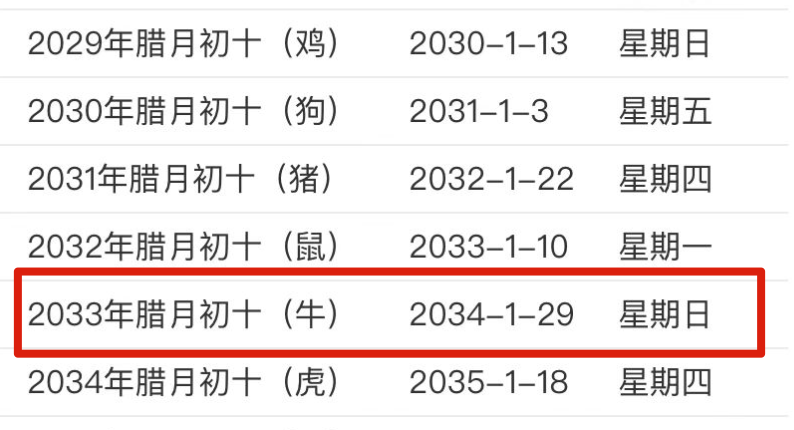
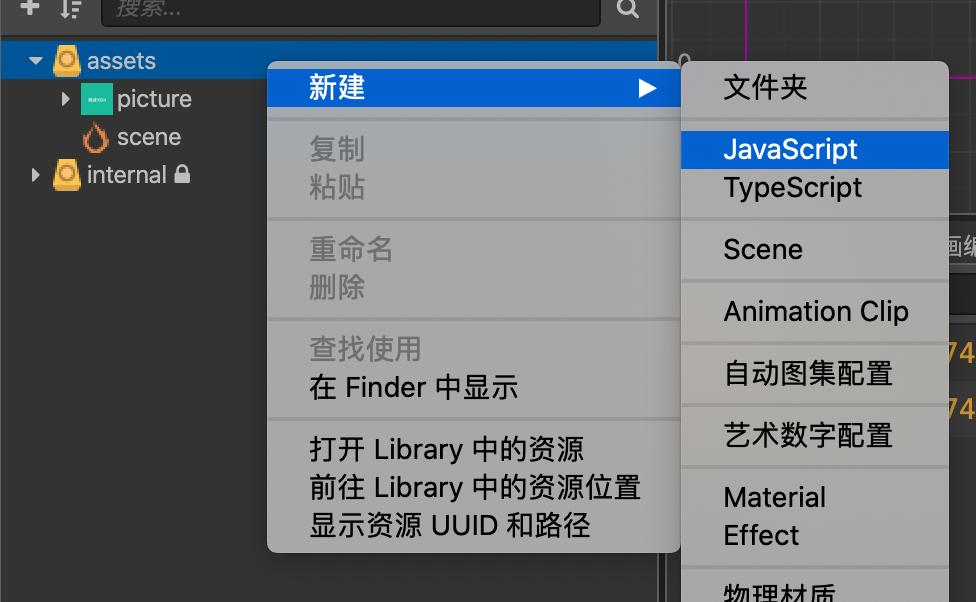
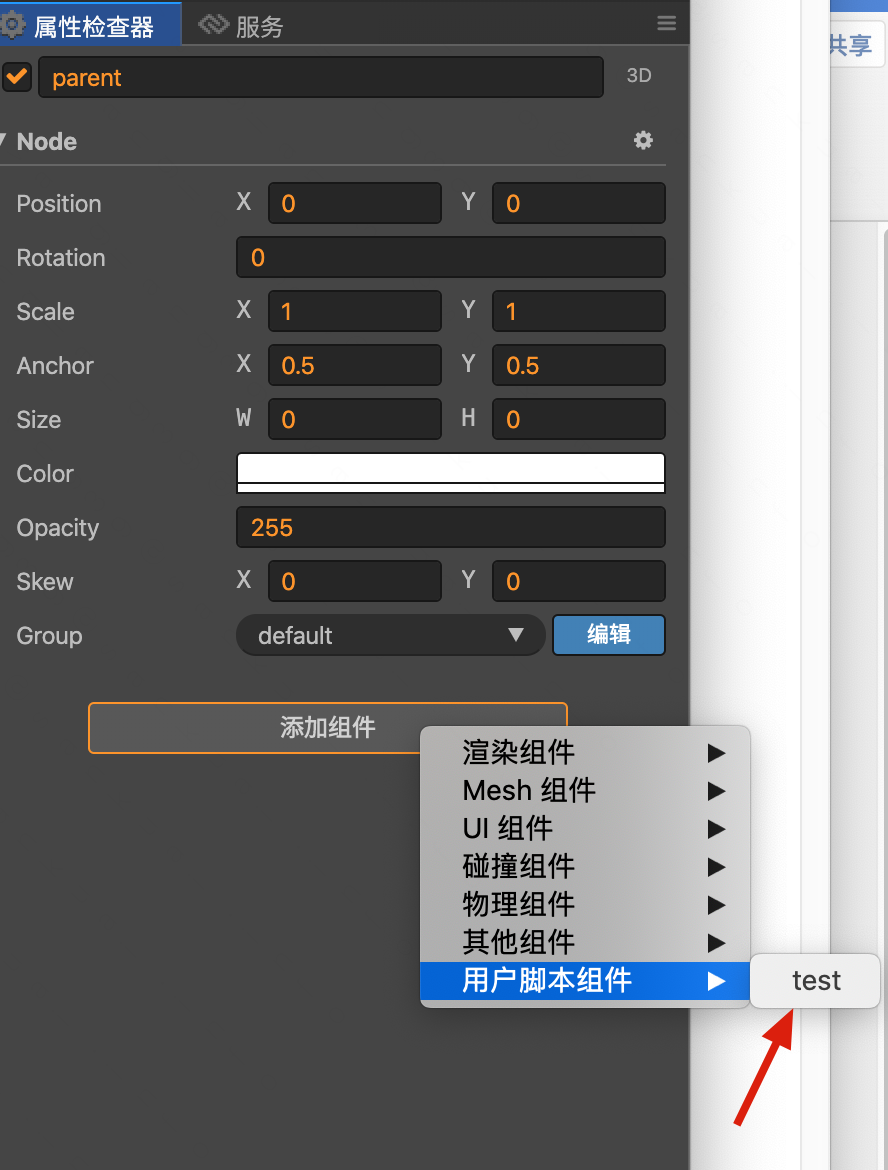
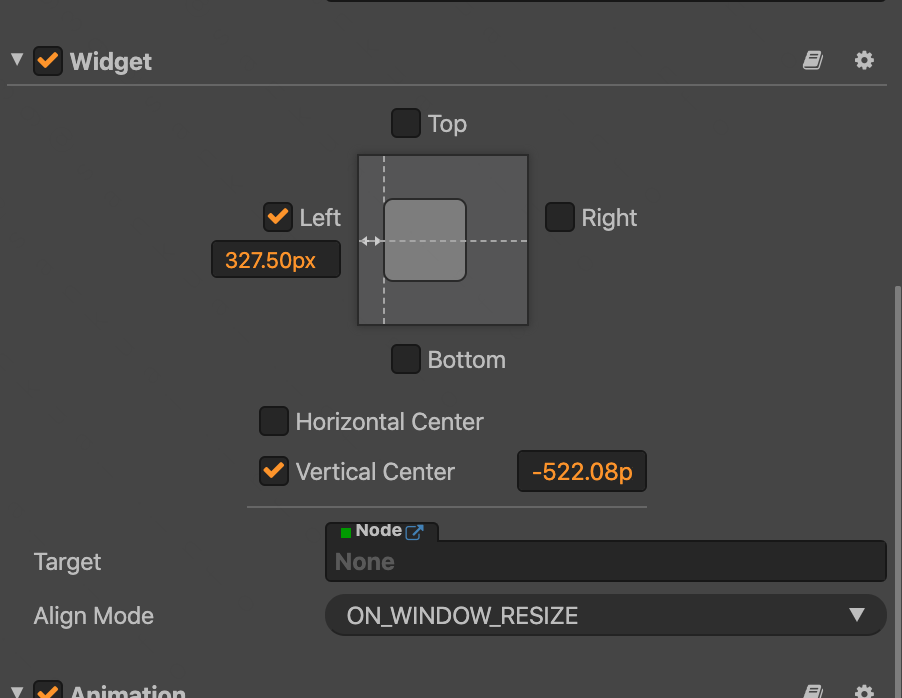
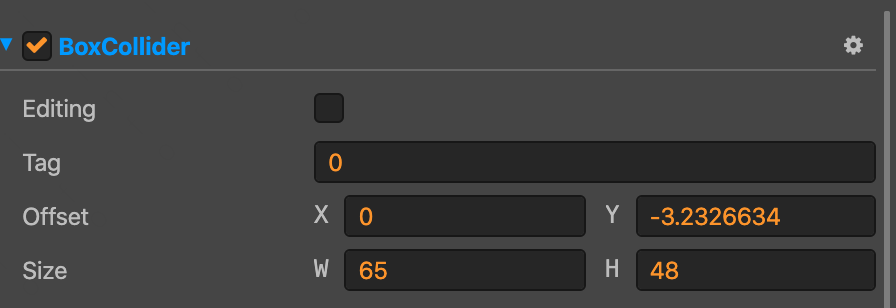
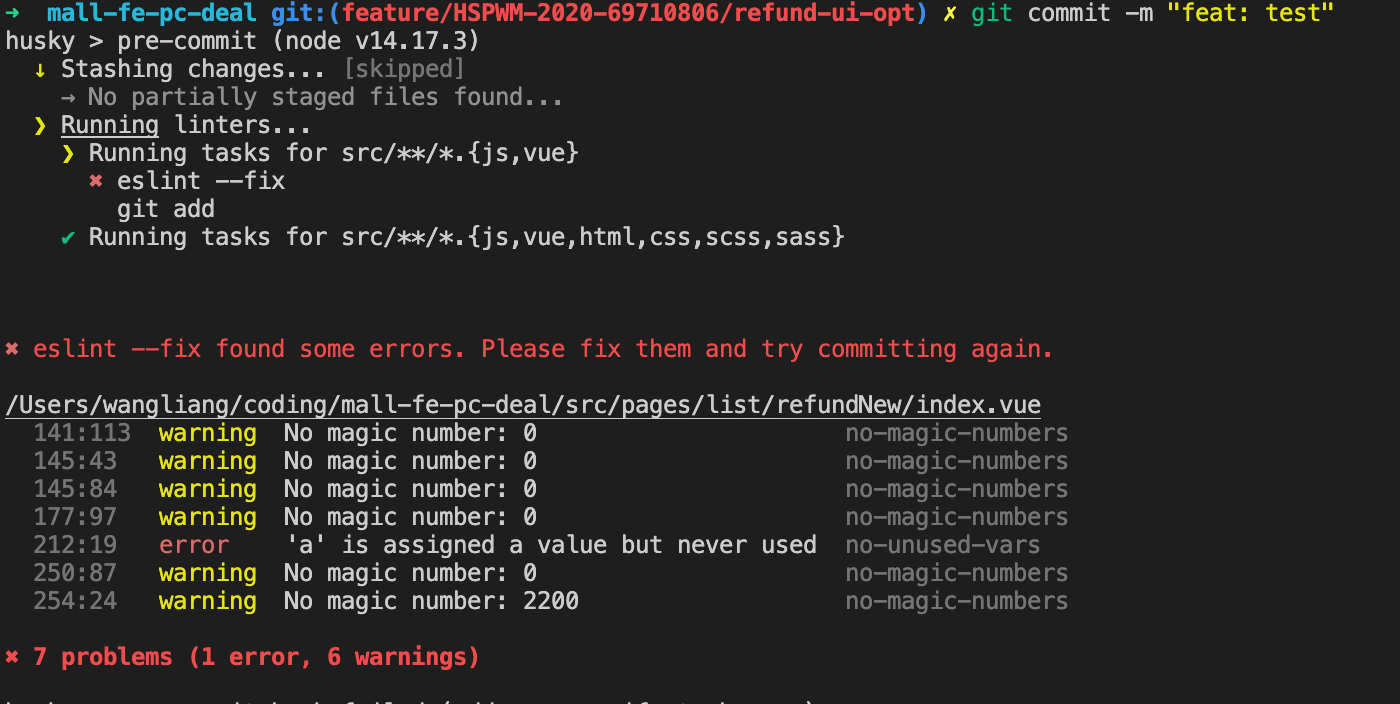
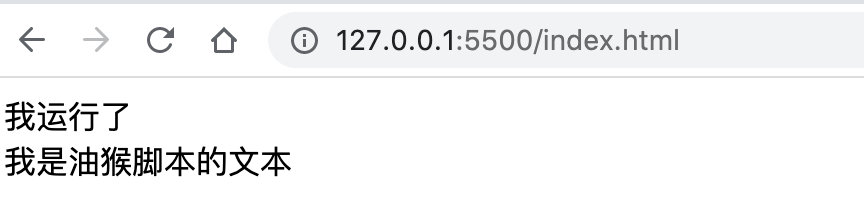
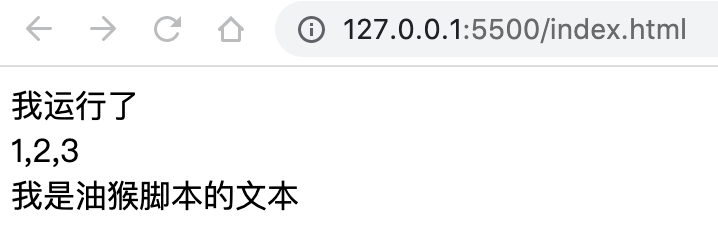
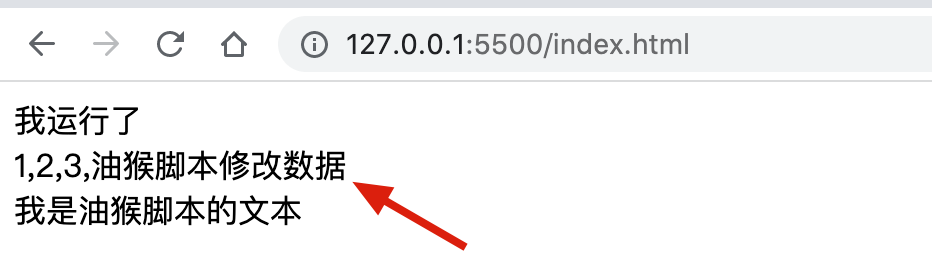
主要是摘抄了一些有感触的点,非原创观点
存在主义哲学
存在主义指的是一种生命能意识到自己的存在,并且以“我”为中心去探索、追求、解决和优化其生命一切的哲学思想。
发展历史
克尔凯郭尔:非此即彼
索伦·奥贝·克尔凯郭尔(又译齐克果、祈克果、吉尔凯高尔等;1813年5月5日—1855年11月11日)是丹麦神学家、哲学家、诗人、社会批评家及宗教作家,一般被视为存在主义的创立者。
_-_(cropped).jpg)
“传统哲学”用最通俗的语言来概括,就是三个字:“盖高楼”。从柏拉图开始,亚里士多德、阿奎那、笛卡尔、洛克、康德、黑格尔,都是体系的建造者,他们都是从一些最基本的概念出发,比如实体、理念、经验、上帝,建造一个自己的哲学大厦,而且几乎每个哲学家都要先把之前哲学家的大厦推倒,从地基开始重建。这是一种上帝视角的哲学,好像世界上发生的一切都尽在哲学家的掌握之中。
在克尔凯郭尔之前都是这种从抽象观念出发的哲学,他反对传统哲学从概念到概念的逻辑推演,开始主张要把个人的生存处境当作哲学的核心问题。
升学填报志愿的时候,上了这个学校就不能上那个,此后的人生就会大不相同;恋爱的时候选择伴侣,和这个人结婚就必须放弃那个人,此后的人生也会大不相同。甚至你今天晚上选择赴哪个饭局,遇到了哪个新朋友,得知了哪个新消息,此后的人生也可能会大不相同。每往前走一步,世界都会逼着我们做出大大小小的选择,而所有的选择都会给我们带来或多或少的焦虑和恐惧。
克尔凯郭尔把这种情绪说成是“面对自由的眩晕”,就好像我们站在悬崖旁边往下看的时候的那种感觉。这种面对自由选择的眩晕感,让他用「非此即彼」做了自己最有名的一本书的书名。
克尔凯郭尔心中的真理,不是传统哲学里那些放之四海皆准的“客观真理”,而是对于他自己而言的“主观的真理”,那就是面对人生的每一个境遇,忠于自己的内心,勇敢地做出“非此即彼”的选择。
陀思妥耶夫斯基:二二得四
费奥多尔·米哈伊洛维奇·陀思妥耶夫斯基1821年11月11日—1881年2月9日,俄国作家。

陀思妥耶夫斯基常常描绘那些生活在社会底层却都有着不同常人想法的角色,这使得他得以19世纪暗潮汹涌的俄国社会中小人物的心理。部分学者认为他是存在主义的奠基人,如美国哲学家瓦尔特·阿诺德·考夫曼、就曾认为《地下室手记》是第一本存在主义的书。
世界是复杂的,并不像二二得四那样简单,因此,某些人“仅仅根据科学和理性的原则”拟定的“幸福体系”,只是空想,是实现不了的。人也是复杂的,不是单凭教育就能改造好的,因为人有个性,有自己的独立人格,每个人的行为都受自己的“自由意愿”支配,有时还有逆反心理,明知不好,对自己不利,却故意为之,以此显示自己的独立存在。
尼采:上帝死了
弗里德里希·威廉·尼采,1844年10月15日—1900年8月25日),是出身德国的哲学家、诗人、文化批评家、古典语言学家和作曲家。

尼采所提出的“上帝已死”成了存在主义的中心论点:如果没有上帝,那么就没有必然的价值或道德律;如果没有必然的价值或道德律,人类精神处境的真相是一片虚无,那人面对虚无该怎么办呢?
从苏格拉底之后,理论家们发明出各种各样的概念、真理、信仰,说在现实世界之上,还有一些更伟大的意义。于是,这些理论掩盖了人生虚无的真相,让人们陷入了幻觉,在幻觉中获得虚假的安慰。这就是理论虚假。
尼采提到了教士们发明的五种麻醉人们的手段。
第一种是催眠,教士们用教义的灌输,用冥想、苦修之类的训练,降低人们对生命意志的要求,让人们进入一种类似冬眠状态,追求一种无我的精神解脱。
第二种手段是机械性的活动,什么时间做礼拜,什么时间忏悔,什么时间劳动,都是规定好的。这些按照明确的指示进行的活动,可以分散人们的注意力,甚至填满人们有限的意识。
第三种是给人微小的快乐,基督教里有各种慈善和表彰,这些都能给人带来微小的快乐,减轻人们的痛苦。
第四种手段,是群体认同,就是让人结成一些小的团体,形成一种相互依赖的关系,这样人们就能把不满的情绪释放在小团体之中,而不会对整体造成威胁。
第五种,是让人的某些感情得到过度的发展,从而压制其他的情感。教士们特别注重培养信徒们在上帝面前的罪责意识,有了这种意识信徒就会心甘情愿地接受苦修和责罚,主动放弃自己的权力意志
现代的生活也完全可以上边的对应,那如果一切都是虚假的呢?
我们赤裸裸地站到了虚无面前,人生没有意义,理论都是虚假,安慰都是幻觉——到这个地步,人已经一无所有了,那么他还拥有什么呢?尼采的回答是,还有一样东西,就是人的生命力。
尼采认为,面对无意义的世界和无意义的生命,人应该立足于现实,直面无意义的荒谬,以强大的生命本能舞蹈,在生命活动中创造出价值。用尼采的话说,就是“成为你自己”。这样一来,虚无不再会让你沮丧和绝望,反倒会给你最广阔的创造自我意义的空间,虚无让人变成了积极的创造者,这就是积极的虚无主义。
「与怪兽搏斗的人要注意,不要让自己也变成怪兽。当你长久凝望深渊,深渊也会回望你。」
虚无主义就是这样一只怪兽,一道深渊,要活出自己的生命意义,我们就需要与这只怪兽搏斗,就需要凝望虚无的深渊。同时我们也要随时提防自己被虚无吞没,丧失对生命真正意义的追求。
胡塞尔:回到事情本身
埃德蒙·古斯塔夫·阿尔布雷希特·胡塞尔(1859年4月8日—1938年4月26日)是一名德国哲学家,现象学创立者。

现代哲学中的现象学可以简单地理解为一种从主观体验上理解意识和世界的学派。 举个例子:
关于桌上的一杯鸡尾酒:
柏拉图会说:在这个酒杯,那个酒杯,所有的、每一个酒杯之下,存在一个“绝对的、完美的、平均的”酒杯。而我们所能看见的、摸到的每一个酒杯,都分享了那个“绝对酒杯”的一部分特征和属性。正是因为在我们面前的那个酒杯也分享了“绝对酒杯”的属性,它才会被我们认知为是一个酒杯。
对于纯粹的经验主义者(譬如休谟和洛克)来说,“表象”是显示在脑海里的感官信息。杏子鸡尾酒酒杯这一物体的“现象”就是我们的视觉接收到的倒锥形形状、透明颜色、光滑材质,加之嗅觉感知到的杏子酒气味、加之手指能触摸到的冰凉的玻璃质感……等等感官信息的集合。
而对于纯粹的理性主义者(譬如笛卡尔)来说,一个人看见酒杯后出现在其脑海里的“酒杯”这个念头,是理性思考得出的酒杯的抽象“理念(idea)”。
胡塞尔会说:只有我看到,触摸到,感受到的酒杯是真实的。
他也并不会止步于此。他会详细描述和归类对鸡尾酒杯的所有体验:视觉、听觉、想象、思考、情绪感受、期望、欲望,以及行动(拿酒杯,喝酒等等)。
胡塞尔确实不是存在主义者,但是在胡塞尔的弟子们的看来,现象学就不仅仅是一个解决传统问题的新工具了,而是开辟出了一大片新的哲学问题。「回到事情本身」这句口号宣告了一种新的真实性,它要求我们不带偏见,尊重意识之中出现的所有现象。哪怕是传统哲学里面完全不屑于讨论的现象,比如无聊、焦虑、忧愁、绝望这些情绪,再比如恶心、幻觉、抑郁、濒死这些体验。
这些情绪和体验都是人在实际的生存境遇里会遇到的问题。但是在传统哲学看来,这些问题太主观、太表面、太非理性,完全入不了他们的法眼。而现象学就可以去关注这些意识对象,因为正确地描述现象,就是认识到了事物的本质。于是,胡塞尔的很多弟子,不约而同地用现象学的方法去观察和描述这些生存现象,存在主义就从现象学里面脱胎而出了。
海德格尔:向死而生
马丁·海德格尔(1889年9月26日—1976年5月26日),德国哲学家,海德格尔对于存在、时间、技术、语言和真理等问题有着独特的见解。代表作有《存在与时间》、《形而上学导论》等。

在海德格尔看来,传统哲学的错误就在于把人类生存里面那些“当下上手”的东西,当做了“现成在手”的东西去理解,这样就脱离了和遗忘了人的实际生活。海德格尔的存在主义,就是要把哲学转向人的实际生存。
当我们拿起锤子钉钉子的时候,不会注意到它的形状、颜色、重量、用途,而是拿起来直接开始钉,这种状态被海德格尔称为“当下上手”(Zuhandenheit)的状态。除非是钉着钉着锤子不好用了,比如说锤头松了,或者太重了我敲不动了,这个时候,我才会停下手上的活儿,仔细端详这个锤子。海德格尔把这种状态叫做“现成在手”(Vorhandenheit)状态。
当然,如果人的全部生活都像用锤子钉钉子一样自然、顺畅,我们也就不需要哲学了。在我们的实际生活中也会遇到很多从“当下上手”到“现成在手”的转变,比如一次工作的变动、一次人际关系的危机、一次亲人的去世,这个时候,正常的生活中断了,原本明显的意义消失了,就好像我们不得不停下敲击,去注视手中的锤子。
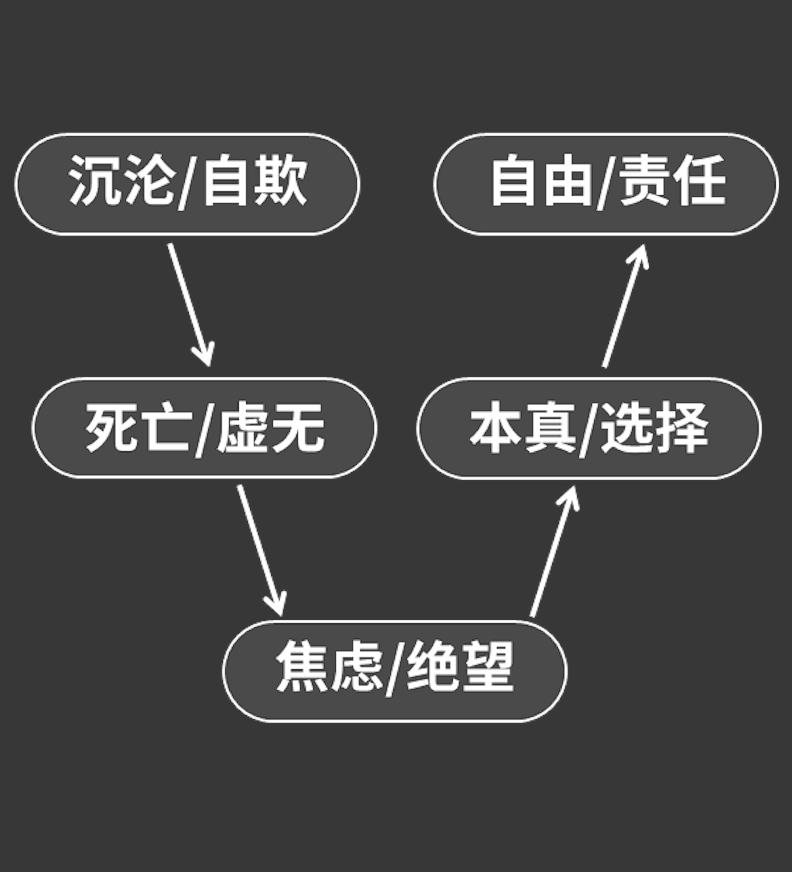
我们被抛入世界之后,大多数时候就是过着“常人”的生活,那是一种没有经过思考,“别人”做什么我也做什么的状态。这种缺乏反思、忘记自我的“常人”状态,就是海德格尔说的“沉沦”状态
我们小的时候,看到别的小朋友要什么,自己也想要;大学生选专业的时候,很多时候是因为父母和老师的希望;毕业工作了,看到别人买LV,自己也想买;当了爹妈,看到别人的孩子上奥数,自己也想给孩子报名;出去旅游,别人拍照打卡的地方,也是我们一定要去留下脚步和照片的地方。
我们大多数的时候,都是这样自觉不自觉地受着别人的影响。而且,我们还经常说不出影响我们的这个“别人”到底是谁,肯定不只是自己的父母、自己身边的一两个同事或者朋友,我们周围还有数量巨大的图书、广告、自媒体,等等,这些东西都在或明或暗地影响着我们。
所有的这些人和东西,组成了一张无形的大网,把我们罩在里面。
和“沉沦”相反的生存状态叫做“本真”(Eingentlichkeit),就是活出真正属于自己的生活。
即便是突然有一个时刻,意识到了自己过的只是“常人”的生活,开始扪心自问,想要做出改变。但是下一刻,可能还是会不由自主地回到那种沉沦的状态,或许只是因为那样更容易,或许只是因为被各种因素掣肘不得不那样。偶尔的灵光乍现还是远远不够的。
比这种“灵光乍现”更能给人当头棒喝的东西,那就是死亡,特别是直面自己终有一死的事实。它更能够迫使我们认识到自己的沉沦状态,甚至能够帮助我们超越沉沦状态
当随口说出“人终有一死”,或者“我终有一死”时,死亡是一个外在于我的东西,一个和我无关的“死亡事件”。就像是谈论一个名人的死,或者谈论第二次世界大战中战死的人数。
我们当然也会悲伤,也会感慨一句:“哎,人生无常,要珍惜生命。”这么说的时候,我们当然也“知道”自己终有一死,但是这种“知道”是一种“闲谈”意义上的、人云亦云的“知道”。
说完了“人生无常,要珍惜生命”,我们还是会该干什么干什么,不管是从心态上还是从做的事情上,都和之前别无二致。这些时候,我们其实是把自己排除在死亡之外的,就像萨洛扬说的“总以为自己不会死”,至少认为死亡离自己很远。这种非常外在的对于死亡的意识,并不会帮助我们进入本真状态。
那什么样的死亡意识可以做到呢?就是真切地与自己将有一死面对面,清楚地认识到,我的死亡是一件最本己的事情,是任何人都不能替代的事情。我只能“亲自去死”,而且我还不知道死亡什么时候会来。
“本真的生活”,在一个意义上确实比沉沦的生活要美好,因为我们毕竟过上了属于自己的生活,而不陷入常人的大网不能自拔。
但是从另一方面讲,如果我们把“美好”理解成确定的、容易的、快乐的,那“本真的生活”很可能一点都不美好,甚至是这些词的反面,它充满了不确定性、困难和痛苦。“本真的生活”没有给我带来任何内容上的确定性,因为海德格尔去掉了良知、本真这些词的道德意味,只强调人的个体性,所以他不会也不能告诉你具体应该去做什么
“向死存在是向着一种可能性的存在,也就是向着此在本身别具一格的可能性的存在。”活出“别具一格的可能性”,就是我们本真的生活。
雅斯贝尔斯:边界性境遇
卡尔·特奥多·雅士培(1883年2月23日—1969年2月26日),旧译雅斯培,德国哲学家和精神病学家,基督教存在主义的代表,1967年他成为瑞士公民。

“边界性境遇”指的是必然与我们的存在联系在一起的,界定了我们作为人的生存的境遇,特别是那些威胁到我们日常生活的安全感和稳定感的境遇。
比如说,我们的生活中一定会经历痛苦,一定会和其他人处于矛盾和斗争之中,一定将会死去。雅斯贝尔斯用了一个很有趣的比喻来描述边界性境遇,他说:“我们看不到边界性境遇背后还有什么别的东西,它们就像一堵墙,我们撞在上面,对它们无能为力……”
那面对这些边界性境遇,我们要怎么应对呢?有两种办法,一种是闭目塞听的态度,假装没有看到它们,这就类似海德格尔说的此在的“沉沦状态”。另一种就是瞪大眼睛直视边界性境遇,把它们当作契机去转变自己的日常生活,通过三重超越实现本真的生存。
第一重超越:在边界性境遇中感受到,自己不仅仅是一个存在着的“东西”或者“物品”,过着没有反思、现成给定的生活,而是真切地感受到“我这个独特的个体”的生存。
在这之后,边界性境遇可以带来第二重超越,从认识上把握这些边界,把它们看作人生的各种非此即彼的可能性。当在死亡的战栗中感受到了自己的生存,开始掂量死亡给我保留了哪些可能性,哪些才是对我的生存真正重要的东西,哪些是可有可无的东西。
再下一步,第三重的超越,就是我基于之前的感受和认识,从我的自由出发,做出实际的行动来明确自己的生存。这样我就从可能性的生存超越到了现实性的生存。
“生存就意味着超越,只要我真的是我自己,我就确信,我并非由于我而是我自己。”
阿伦特:政治性的存在
汉娜·阿伦特(1906年10月14日—1975年12月4日),是政治哲学家、作家和纳粹大屠杀幸存者。
.jpg)
最有名的观点应该是“恶的平庸性”或者“平庸之恶”了。
《艾希曼在耶路撒冷》,里面详细地记录了以色列审判纳粹高官艾希曼的过程。阿伦特发现,参与了屠杀很多犹太人的艾希曼,其实并不是人们想象中的恶魔,而仅仅是一个不会自己思考,平庸到可笑的官僚。
阿伦特很有洞见地看到了死亡的反面:人的出生。表面看来,我们是赤裸裸、孤零零地来到这个世界上的,就像我们终将孤身一人离开那样。但是如果我们深想一步就会发现,绝非如此。
出生这个事件,恰恰显示了个人与共同体密不可分。我是由父母生出来的,我的父母又来自他们的父母,我生活在某个家庭、某个社区、某个国家之中。如果说死亡是把个人与他人扯开、孤立起来的境遇,那出生就是一种把个体与他人牢牢绑定在一起的境遇。
阿伦特还更进一步,认为死亡其实也不像海德格尔说的那么孤独,也带有很强的共同体色彩。阿伦特不否认,我们自己的选择和行动塑造了每个人生存的意义。但是一个人完整的人生意义,只有在他死后才能盖棺定论。而这个盖棺定论的工作,必然只能交给他所属的共同体去完成。
死亡让一个人把自己完整的生命意义交给他所属的共同体,让共同体对他形成一个前后连贯的“叙事”或者说“故事”。至于这个共同体是一个家庭、一个工作单位,还是一个国家,或者整个世界,取决于一个人生前做了哪些事,但是不管怎样,给人生赋予完整意义的工作都属于一个共同体
有某个共同体,就意味着一群人生活在一个共同的境遇之中;同时也就意味着有复数的、多元的人。共同的境遇和彼此不同的个体,正是我们“政治性”的核心特征。那些塑造了“自我”的、我自由选择的行动,看似是我这个个体进行的选择,其实都是和我所处的共同体,以及我的政治性密不可分的。
萨特:存在先于本质
让-保罗·夏尔·艾马尔·萨特(1905年6月21日—1980年4月15日),是法国哲学家、剧作家、小说家、编剧、政治活动家、传记作家和文学评论家。他是存在主义]和现象学哲学的关键人物之一,主要哲学著作《存在与虚无》。

存在就是虚无
萨特把物的那种被决定的、不能改变的存在,叫做“自在”的存在。把人的这种“有待形成”的、不固定的存在,叫做“自为”的存在,就是自己“为自己”而存在。你可以记住这一点:自在的存在有一个固定不变的本质;而自为的存在没有固定的本质,它的本质是可以变化的
萨特坐在花神咖啡馆里,他在思考这样一个问题:人的存在和物的存在究竟有什么区别?我们都知道,人是有意识的,而物品没有。但有意识的人和没有意识的物,究竟不同在哪里呢?
萨特看着眼前忙碌的服务员,又看着自己面前的杯子,他问自己:我们说这个服务员是一个服务员,和说这个杯子是一个杯子,这两种说法是同一回事吗?他感到大不相同!
说这个服务员是一个服务员,并不是注定的。如果这个人下班了,甚至辞职了,他就不再是一个服务员了。一个人是什么,这是可以改变的。
但杯子就不同了,杯子不能改变自己,它被判定为一个杯子,别无选择地就是一个杯子,就算你把它打碎了,它仍然是一个碎掉的杯子,而且杯子甚至不能自己选择把自己打碎。
你可能发现了,其中关键的区别,就在于有没有意识和意识支配的行动。为什么人的存在可以改变?因为人并没有什么预定的本质,人的存在原本就是虚无,它的本质是“有待形成”的。
存在先于本质
哲学里,至少从柏拉图开始,主流的观点都是本质先于存在,比如说人的本质就是理性,圆形的本质就是与某个点距离相等的点的集合。这些带有普遍性的本质,在某个具体的人和具体的圆形存在之前就已经确定了,所以说“本质先于存在”。
但是在萨特看来,只有自在的存在,也就是那些没有意识的东西,才是“本质先于存在”的。一棵树、一张桌子,在它们存在之前,本质就已经确定了,一棵柳树苗就会长成柳树,一张桌子就是供人写字、吃饭的家具。
但是对于人这种“自为的存在”来讲,就完全不同了。因为人从根本上讲就是虚无,而虚无就是没有任何本质。一个婴儿在出生的时候得以存在,但是他这个存在是没有本质的,我们不能说他是好是坏,是工程师还是公务员,甚至不能说他是不是理性的。
因为在拥有存在的时候,他没有任何的确定性,他的一生充满了开放性,有无穷多的可能性,只有通过他日后有意识的选择,才能获得某种稳定的性质,拥有某种类似“本质”的东西。
虚无奠定自由
因为存在先于本质,那么就没有什么预先给定的东西把我们固定住、束缚住,就意味着我们永远可以超越“过去的本质”、“现在的本质”去追求“未来”。
换句话说,人永远不会“是”什么,而是永远都正在“成为”什么。在这个意义上,人是自由的,甚至人就是自由本身。还是那个比喻,站到舞台上,你可以扮演任何角色,每一个角色都不是你本人,但正因为如此,你的行动才是自由,因为你没有被任何一个角色所定义。
人是被判定为自由的,自由就是人的命运。人唯一的不自由就是不能摆脱自由。不论你是多么渺小,不论你受到多少外在的限制,在根本上你都是自由的。
自由的负重
自由选择必定会带来后果,那么谁来为这个后果负责?萨特说,没有任何别人可以承担这份责任,你做出了选择,你就要独自承担责任。但“承担责任”究竟是什么意思呢?为什么只能独自承担,难道这份责任就不能跟别人来分担吗?萨特的回答是:不能。
每个人的生活都充满大大小小的选择,比如毕业之后继续深造还是直接工作,选择什么职业,要不要结婚,要不要孩子……所有的选择都会有后果,我们就生活在自己选择的后果之中,这些后果也在塑造我们自己。所以我们会在乎选择的好坏对错,谁都不想过后悔的人生,我们都会希望自己的选择有一个坚实可靠的依据
任何信条、任何主义,或者别人的建议,都不能成为你的借口。萨特认为,这些说辞都只是自欺欺人,是用来逃避自己的责任。开个夸张点的玩笑,假如你和你的伴侣分手了,朋友来安慰你,会说“这不是你的错”。但萨特可能就会说,这就是你的错,是你自己选择的人,是你自己谈的恋爱,这个结果当然是你的责任。
独自承担责任是什么意思?就是自己做自己的立法者,为自己做出的每一个选择承担绝对的责任。你看,从“存在就是虚无”,萨特推出了人的绝对自由,而从绝对的自由,萨特又推出了绝对的责任。这是一份非常沉重的负担
他人即地狱
萨特认为,人总是要维护自己的主体性,所以人与人之间一定会为了争夺主体性而斗争。每个人在和他人相处的时候,都想把他人变成客体,以此来维护自己的主体性和自由。
萨特举了一个例子,说你走在街上,迎面过来一个陌生人,用眼光上下打量你,你会觉得很不舒服。为什么你会不舒服?萨特解释说,别人注视你时,他下意识地就把你变成了他观察的客体。在这个注视中,他是主导者,你只是被他观看的物品;他要实现自己的主体性,代价就是把你的主体性给否定掉,把你物化。所以,你会下意识地回避对方的注视。但你也可以反抗,他看你一眼,你就回看他一眼,用你的注视把他变成客体。
在萨特看来,人和人的交往就是这样,总是在为了争夺主体性而斗争。即使是在爱情当中也不例外。萨特说,我们想象中的浪漫爱情是一个骗局,那种不分彼此、合二为一的爱情体验,只不过是刚刚开始时候的幻觉罢了。爱情同样充满了为争夺主体性而展开的冲突和斗争,到最后要么是受虐,在羞耻中享受快乐,要么是施虐,在内疚中感到愉悦。
萨特的一个个人生选择,都体现出他对自由和本真生活的向往,他用自己的一生在践行存在主义哲学,自由选择和积极行动。
萨特是一位世界闻名的哲学家,但他从来没有在任何高等学府正式任教。他虽然撰写了很多严肃的哲学论文和著作,却也花了很多精力去写小说和戏剧,甚至获得了诺贝尔文学奖。
但更令人印象深刻的是,获奖之后,他公开拒绝领奖,理由是他“不接受任何来自官方的荣誉”。这引起了很大的争议,有人说这其实是萨特爱慕虚荣的表现,觉得获得诺贝尔奖还不够突出,还要成为第一个主动拒绝诺奖的人。
萨特和波伏瓦在上大学时相识,彼此志趣相投,很快就陷入了恋情。但他们都认为人是绝对自由的,不必受到习俗制度的约束,于是签订了一个奇特的爱情契约,作为彼此的伴侣,但永不结婚。他们的爱情是开放的,不排除与其他人发生亲密关系,但彼此坦诚,不会隐瞒。而且这个契约的有效期只有两年,每过两年双方就要确认一次,是否还继续这段伴侣关系。
这个契约足足延续了 51 年,从萨特 24 岁直到 75 岁去世,两人真的做到了相伴一生。
萨特不仅是哲学家和作家,还是一位社会政治活动家,甚至被哲学家福柯称为“法国最后的公共知识分子”。1968 年,法国又发生了史称“五月风暴”的抗议活动。萨特和波伏瓦发表声明支持这场运动,并且走上街头散发传单,直接参与抗议活动,结果被警察逮捕了。
但当时的法国总统戴高乐迅速介入干预,要求警方放人。戴高乐说,“我们能把伏尔泰关进监狱吗?不能,所以赶快把萨特放了吧”。萨特当时在法国的影响力,甚至足以与启蒙时代的伏尔泰相比。
波伏娃:模糊性的道德
西蒙·露西·埃内斯蒂娜·玛丽·贝特朗·德·波伏娃(1908年1月9日—1986年4月14日),或称西蒙娜·德·波伏娃、西蒙娜·波伏娃,是出身法国的作家、存在主义哲学家、政治活动家、女权主义者、社会主义者和社会理论家。她的思想与学说等,对女权主义式存在主义和女权主义理论都产生了重大影响,以《第二性》闻名。

在波伏瓦看来,人从来不是孤独的存在,不能孤立地行使自由。像萨特那样强调一个人绝对的自由是没有意义的。我们总是和他人联系在一起,所以我们的自由总是有限的,与他人相互制约的。我们不能行使绝对的自由,而只能行使在某个情境中的相对自由。
一个人如果试图对抗他人,把他人当作“地狱”,他就会失去自由,也失去自我。相比萨特,波伏瓦更愿意强调人际关系中积极的方面,她认为我们之所以能够成为现在的自己,是因为出现在我们生命中的其他人,有父母、老师、朋友、爱人,还有陌生人,自我是不断被他人塑造的,始终处于一种“生成”的过程之中。
从人的这种总是与他人互动的生存状态,波伏瓦提出了一个很有意思的概念,叫做“模糊性的道德”,或者也可以翻译成“模棱两可的道德”。在波伏瓦看来,人类在本质上就带有模棱两可性或者模糊性。
我们既是主体也是客体,既是意识也是物质,既是理性也是非理性,既是自由的也是不自由的,既相互分离又相互依赖。但是传统哲学总是想要打压这种模糊性,把人概括成“理性的动物”、“思维的主体”,或者“物质的构成”
加缪:荒诞
阿尔贝·加缪(1913年11月7日—1960年1月4日),生于法属阿尔及利亚蒙多维城,法国小说家、哲学家、戏剧家、评论家,其于 1957 年获得诺贝尔文学奖。加缪位于20世纪最有名的和最重要的的法国作家之列。代表作有《局外人》、《西西弗神话》、《鼠疫》等。

“自杀是唯一真正严肃的哲学问题。判断人生值不值得活,这本身就是在回答哲学的根本问题。”
《西西弗神话》中描写了希腊神话里的一位国王西西弗,因为欺骗诸神,被罚在地狱里推着一块大石头上山。每当他费尽力气把石头推上山,石头又会重新滑落,西西弗只能从头再来。你还能想象比这更悲催的人生吗?这个神话故事最好地展现了加缪讨论自杀问题的背景:如果人生注定是没有意义的、荒谬的,我们是不是应该选择自杀呢?
人一定要追问意义,但是又注定不可能得到期待的答案,这就是荒谬感的根源,荒谬就是人与世界之间必然的联系。
如果世界注定没有意义,如果人生注定荒谬,我们能怎么办呢?面对“我们是否应该自杀?”的问题,加缪又能给出什么样答案呢?他给出的答案是:坦然接受这个世界的荒谬性,用真诚的心过好当下的生活,感受生活中的美好,这就是我们能够赋予生活的全部意义。
自杀绝对不是对抗荒谬的办法,因为自杀意味着承认荒谬的胜利,那不是对抗,而是投降。2唯有直面荒谬,珍惜当下,才能创造出此时此地的意义,哪怕这种意义只是闻到了海风的气息,只是又推着石头前进了一寸。
“登上顶峰的斗争本身足以充实人的心灵。应该设想,西西弗斯是幸福的。”
总结
假如恶魔在某一天或某个夜晚闯入你最难耐的孤寂中,并对你说:‘你现在和过去的生活,就是你今后的生活。它将周而复始,不断重复,绝无新意,你生活中的每种痛苦、欢乐、思想、叹息,以及一切大大小小、无可言说的事情都会在你身上重现,会以同样的顺序降临’。”(尼采:《快乐的科学》341)如果你听到这话瘫软在地,那你过的就不是本真的生活;如果你面对这个恶魔说,我从来没有听过比这更神圣的话。你会把你所有的人生选择重新选一遍,那么你过的就是本真的生活,忠于自己的生活。
相关资料
得到:刘玮·存在主义哲学20讲
得到:刘擎·西方现代思想
《哲学家们都干了些什么》
《存在主义咖啡馆:自由、存在和杏子鸡尾酒 》
《苏菲的世界》
chatGPT
维基百科
]]>