如果最开始接触的是 C/C++ 语言,一定会对指针这个概念感到困惑,一不小心就会被它绕进去,不知所云。最近看 linux 内核的一些代码,自己又开始接触了指针的一些东西,索性也就总结一下,写一下自己目前对于它的理解。
关于地址
在程序中,我们会声明一些变量,然后将数据存到变量中。例如 int a = 3。而在计算机内部,这个值会存到内存(RAM)中。存的话就会涉及存到哪里,因此内存会进行编址。
就像一栋楼的每户人家,会有门牌号,101,102,103,201,202…
内存也是一样的道理,会对内存空间进行分配,而最小的分配单元是字节。换句话说,一个地址对于一个字节,也就是 8 比特。
还有一个问题,用几位数进行编址,早几年都是采用 32 个比特就行编址,现在大部分都是 64 个比特了。
如果用 32 个比特进行编址,那么我们的地址数量就是 2 的 32 次方,$1K = 2^{10}$,$1M = 2^{20}$,$1G = 2^{30}$,所以 $2^{32} = 2^2 * 2^{30} = 4G$,也就是我们有 4G 个地址,注意这里 4G 就是一个数字,它是二进制下的简写形式,本质上和十进制下的 1, 1231, 989932 这些数字一样。
又因为一个地址对应一个字节,所以我们总共有 4G 个字节,即 4GB。这也是我们常说的,32 位操作系统下最多支持 4G 内存条的原因了。内存再增加的话,没有多余的地址去表示,也就没用了。
最后,关于地址和内存我们可以抽象成下边的图。因为 32 位太长了,所以书写上我们用 16 进制书写,每 4 位二进制对应一位 16 进制。
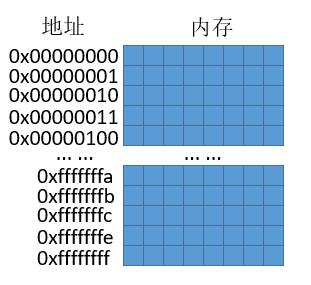
而对于 int a = 3,操作系统会帮我们在内存中找一个地址,然后把 3 放入内存中,变成下边的样子。
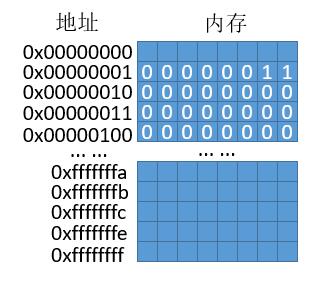
操作系统把 3 放到了地址 0x00000001 的位置,此外需要注意的是 int 是四个字节,所以需要占据四个地址,而对于 3 写成二进制就是 0000000000...11,30 个 0。
接下来的问题,因为是四个字节,那么对于 00000000 00000000 00000000 00000011,我们先存储高位的 00000000 还是低位的 00000011 呢?这和处理器架构有关,比如常见的Intel x86系列是小端序,也就是先存低位的 0000011 ,如上图所示。相应的另外一种就是大端序,先存高位的 00000000。
那么我们如果想知道 a 存放数据的地址该怎么办呢?C/C++ 为我们提供了 & 这个操作符,可以得到变量的首地址。
因为 &a 得到的就是一个数字,即 0x00000001。那么,如果我们想把它存到一个变量中,我们需要声明一个什么类型呢?
关于指针
接着上边的问题,有没有一个专门存地址的类型呀,比如 pointer ,然后 pointer p = &a。或者更直接点,地址不就是一个数字吗,我们也用 int 去存,比如 int p = &a 。这样做看起来没什么问题,我们确实可以把地址存到一个变量中。但有一个问题,怎么逆回去呢?
现在,p 保存了数字 3 的首地址,怎么得到 p 地址对应的数据呢?直接把 p 地址对应的字节拿出来吗?显然是不够的,因为 int 是四个字节,我们应该把连续的四个字节拿出来组成一个数。
而不同类型 double、int 、char 所需要的字节数是不一样的,所以只有首地址是不够的,我们还需要知道这个地址对应的类型占几个字节。
所以我们需要 double 指针类型去存 double 类型的地址,也需要 int 指针类型去存 int 类型的地址,还需要 char 指针类型去存 char 类型的地址。
为了方便,我们就规定在一种类型后边加 * 号就来表示该类型的指针,也就是去存该类型的地址。
所以 int a = 3,我们就可以 int* p = &a。
现在 p 就存了 a 的地址,同时也知道了当前存的是 int 类型的地址,也就是 4 个字节,我们就可以把 p 对应的地址中的数据正确的拿出来了。
同样的,C/C++ 中规定了 * 操作符来从对应指针类型存放的地址中拿出相应数据。
int b = *p,此时 b 得到的就是 3 了。
所以说了这么多,指针其实就是一种存地址的类型,而又因为不同类型所占的字节数不同,所以只有地址还不够,就有了不同的类型指针。
做个实验,看看我们能否直接通过地址来得到对应的数据。
1 | int a = 1024; |
对于 p2 我们需要把它强转成 int* 类型,作用就是告诉计算机当前的这个数字是个地址,并且对应存储的是 int 类型的数字。
关于数组
对于数组,int a[3] = {1,2,3},我们知道 a[0] 就是 1,a[1] 就是 2 ,a[2] 就是 3。
a 是一个 int[3] 类型。当然如果 int a[4] = {1,2,3,4},那么 a 就是一个 int[4] 类型。
int[3] 类型和 int* 类型有一个共同点就是,它们存的都是地址。区别在于 int[3] 类型还代表总共连续有 3 个数字。
因此对于 int[3] 类型,我们得到当前有多少个数字。
1 | int a[3] = {1,2,3} |
如果我们人为的把 a 赋值过来,也就是 int* b = a,怎么取到 a[0] 的值呢?只需要 *b 即可。怎么知道 a[1] 的值呢?只需要 *(b + 1),注意这里对 b 进行加 1,事实上并不只是加了 1。因为 b 是一个 int 类型的指针,所以加一的含义是移动到下一个元素的首位置,所以会加 4。我们来验证下。
1 | int a [] = {1, 2, 3}; |
00DDF8AC 和 00DDF8B0 确实是差了 4。此外 *(b+1) 和 b[1] 是完全等价的,可以互换。
a 是数组元素的首地址,此外我们知道 a[0] 是第一个元素,我们之前用过的取地址符 & 在这里也可以用到。
1 | int a [] = {1, 2, 3}; |
当然,因为 a 是一个地址,我们也可以直接对 a 进行取元素。
1 | cout << *a << endl; //1 |
既然 int[3] 和 int* 都存的地址,我们把 a 赋值给了 b,那么我们能把 b 赋值给 a 吗?
1 | int a [] = {1, 2, 3}; |
答案是否定的,虽然两者都存的是一个地址,但是 int[3] 还有一个信息,那就是代表有连续的 3 个元素,而指针 int* 仅仅是一个地址信息,所以不能直接把 int* b 赋值给 int[3] a。此外还有一个原因,数组名 a 是一个 const 变量,不可更改。
多级指针
我们知道指针存的是一个普通类型的地址,它就是一个数字,也需要放到内存中,就会有对应的地址,那么这个地址如果想放到一个变量中,放到什么类型呢?也就是指针的指针。
1 | int a = 3; |
**d 保存了 3 所在的地址,而 **d 也需要存在内存中,它存到了 004FFDB4 的地方,由 *d 进行保存。同样的 *d 也需要存到内存中,它存到了 004FFDA8 的地方,由 d 来保存,如下图所示。
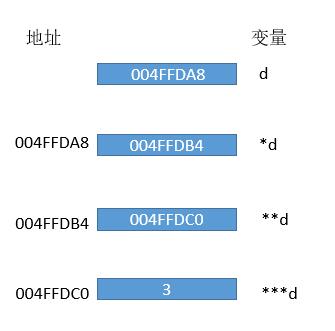
事实上,* 的数量只是表明我们需要 * 几次才能拿到数据,比如 int ***d = &c,所以我们对 d 进行三次的 * 操作就能拿到最初的元素而不是地址。
但不管是 int * 还是 int ** 还是 int **** 类型,它们都存的只是地址,没有其他的信息,所以我们可以进行强制转换。
1 | int a = 3; |
我们看到它输出的是 00000003 ,因为程序以为进行 * 一次操作后得到的是一个地址,但事实上,我们已经得到了原本的数值。
当然上边的这些写法,仅用于对指针的理解,实际上不要这样做。
多维数组
二维数组我们也经常用到,比如下边的例子。就相当于一个二维矩阵。
1 | int a[2][3] = {{1,2,3},{4,5,6}} |
因此 a[1][1] 就会取到 5。
那么 a 是什么类型呢? int[2][3] 类型,含义就是有连续的两个 int[3] 类型,和一维数组一样,存的也是一个地址。
那么二级指针和二维数组什么关系呢?是不是直接把二维数组的变量赋值给二级指针就可以了。
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
程序运行会直接崩溃,想一下为什么。
如果是 cout << a[1][1] << endl 肯定是没有问题的,我们拆分一下 a[1][1] 做了什么。
前半部分的 a[1] 得到的是一个 int[3] 类型,也就是之前分析的一维数组,换言之得到了一个地址。因此可以用一维指针存储,然后再进行 (a[1])[1] 就会得到 5 了。
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
回到最开始的问题,我们把 a 强制赋值给了 b,int **b = (int **)a;,然后 b[1][1] 会得到什么呢?
b[1][1] 等价于 *(*(b + 1) + 1),b 是 int 类型的指针,所以 b + 1 相当于在 b 存储的地址上加 4。那么 *(b + 1) 得到的其实是一个数字,也就是二维数组中的第二个元素 2,那么再进行加 1,最后执行的是 *(2 + 1),把 0x00000003 当成地址去取元素,而这个地址是受保护的,不能随便去取,所以程序也就崩溃了。
所以怎么让 b 数组输出 a[1][1] 呢?
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
为什么可以这样,因为二维数组在内存中也是线性存储的,我们把所有的地址打印一下。
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
把它们的地址依次打印输出,会发现它们是连续的,并且两两相差 4。
而 b[4] 实际上就相当于在 b 的地址上加 4 * 4 = 16,也就是 0099FBF4 + 10 = 0099FBF4,这个地址就对应的是 a[1][1] ,也就是 5 了。
此外,首地址 0099FBF4 其实也有三种得到的方法。
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
其中,a 和 a[0] 存的其实都是地址,而且是相等的。但类型不同,a 的类型是 int[2][3] ,而 a[0] 的类型是int[3]。
一维数组可以用指针来保存其地址,二维数组刚才探讨了不能用二级指针表示,那么怎么办呢?
一维数组中,对于 int a [2] 代表连续的 2 个 int,所以我们可以定义一个 int * 指针来保存 a 。
二维数组中,对于 int a [2][3] 代表连续的 2 个 int[3],同理我们可以定义一个 int * [3] 指针来保存 a 。
写法的话就是 int (*b) [3] = a。
这样的话,除了 b 不知道有几个 int[3] 以外,b 和 a 就可以混用了。
1 | int a[2][3] = { { 1,2,3 },{ 4,5,6 } }; |
这里的话,要注意的是,*(b + 1) ,由于此时 b 是 int [3] 类型的指针,所以其实是加了 3 * 4 = 12。
1 | cout << b << endl; //012FF774 |
总之,最主要的就是要抓住指针存储的是地址,然后有各种类型的指针,当对其进行加一操作的时候,加的数值是该类型的大小。
更多
C/C++ 中的指针知识就写这么多了,另外我们平常在描述一些数据结构和算法的时候也会提到指针这个词,其实和上边的关系并不大,这里的指针就是字面意思。
举个例子,找出有序数字的两个数字,使得其和是 sum 的时候,常常用到双指针法。
1 | 1 4 6 7 8 sum = 13 |
此外,当我们谈论链表的时候,也常常说 next 指针,但对于一些更高层的语言,比如 java,其实是没有我们上边分析的指针的概念的,我们并不能知道变量的地址。
1 | public class Node{ |
比如上边的例子,我们常常说 next 指针,但其实和 C/C++ 中的指针还是有区别的,对于 java ,next 其实是个引用。
最后
其实本来是想总结 linux 内核源码中链表的实现的,没想到将指针概念就讲了这么多,哈哈,那就下篇文章写 linux 的链表吧,非常有意思,会对指针有个更深的了解。
前边讲了那么多,其实我们只要把握住一点,指针类型变量存的是地址,然后有各种各样类型的指针,类型是告诉我们当通过这个地址取元素的时候,要取连续几个字节的数据。
