开始
先考虑下边的问题。

我们知道 length 就是字符串的字符数,所以输出的依次是 2,1,1,对吗?
探索一
我们知道,计算机里只能存 0 和 1,换言之,只能存数字,而我们现在在屏幕上看到的文字只是将数字对应到图形而已。
早期的 ASCII 码就是典型的例子,如下图,为了书写方便我在数字前边加了 0x 代表是 16 进制。
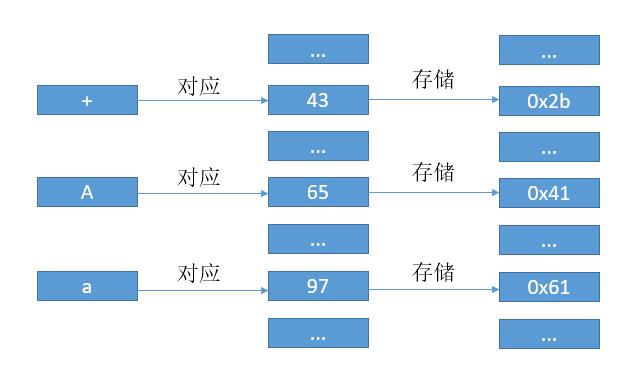
我们用 106 代表 ‘ j ‘,115 代表 ‘ s ‘。然后如果用 ASCII 码表示 “js” 的话,其实就是 0110101001110011 ,然后每 8 位也就是一个字节组成一个数字,根据对应关系电脑把本来的数字转换成了字符 “js” 展示到了我们面前。
有一个缺点就是 ASCII 码是 8 位,那么只能表示 $2^8$ 个数字,也就是 256 个数字,这对于英文字母已经足够了。但是对于汉字的话,还远远不够。
探索二
所以我们加 1 个字节,用两个字节的数字去对应汉字,$2^{16}$ 也就是 65536,肯定足够了。
当然,每个国家都会这样想,然后都制定了自己的语言相应的对应规则,这当然不方便大家在互联网上互通有无,如果本机不知道对应国家的编码对应关系,从而会造成乱码。所以后来有了 Unicode。
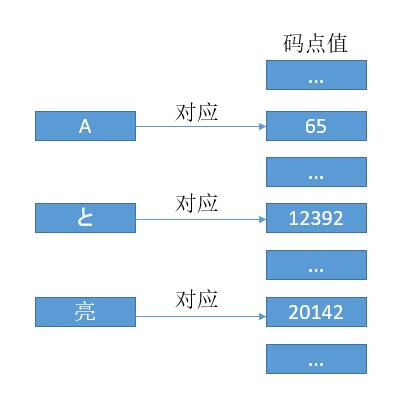
我们用 0x000000 - 0x10FFFF 这么多的数字去对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。从 0x010000 - 0x10FFFF 再划分为其他平面。
和 ASCII 码一样,我们可以把每个符号对应于一个数字,这个数字我们也把它叫做码点值。
有了对应关系,我们可以像 ASCII 码那样去存了。当然这里的话因为每个字符都对应 24 比特位的数字,所以我们就用 3 个字节去存它吧。但是考虑到 CPU 的寄存器都是 8 位,16 位,32 位。。。翻倍来的,所以即使用 24 位,最终还得转到 32 位,所以我们直接用 32 位吧。
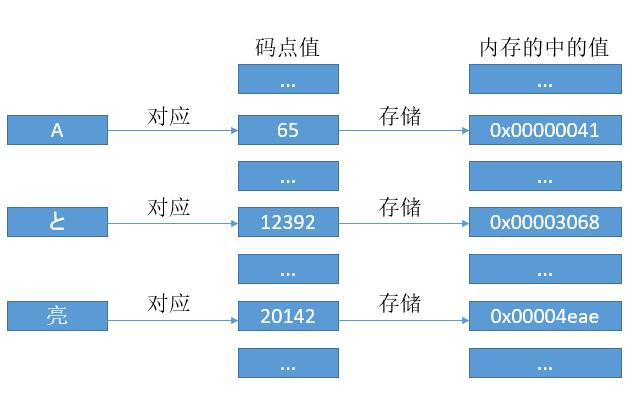
是的,这就是传说中的 UTF - 32 编码,简单明了,码点值是多少,内存中就存多少。
探索三
UTF - 32 缺点很明显了,字母 A 原本只需要 1 个字节去存储,而现在却用了 4 个字节去存,大部分位置都是 0。
我们为什么要多存那么多零呢?能不能 A 只存 0x41,亮只存 0x4eae。如果 A亮这个字符串放到内存中就是 0x414eae。问题来了,计算机怎么知道,几个字节代表一个字符呢?是 0x41呢?还是 0x414e 呢?还是 0x414eae?
于是,就有了 UTF - 8,将码点值进行一定的转换再去存储。
把阮一峰老师的讲解搬过来。
2
3
4
5
6
7
8
> (十六进制) | (二进制)
> ----------------------+---------------------------------------------
> 0000 0000 - 0000 007F | 0xxxxxxx
> 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx
> 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
> 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
>
根据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是
0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。下面,还是以汉字
严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最右边二进制位开始,依次从右往左填入上边格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4 B8 A5。
让我们再看下「亮」,码点值是0x4eae,二进制就是 100111010101110,同样符合第三行,即格式是1110xxxx 10xxxxxx 10xxxxxx。从亮的最右边二进制位开始,依次从右往左填入上边格式中的x,多出的位补0。这样就得到了,亮的 UTF-8 编码是 1110(0100) 10(111010) 10(101110),16 进制就是 e4 ba ae。
所以现在的对应关系变成了下边的样子。
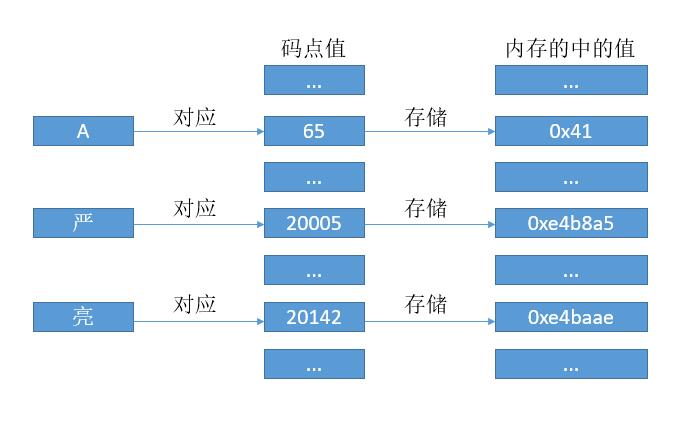
和 UTF - 32 不同之处在于,我们不再用 4 个字节存储码点值,而是通过规则转换后再存储,这样的好处就是之前的A的话就只需 1 个字节就够了,而其他的可能是 2 个或 3 个,4 个字节,所以 UTF - 8 也叫变字长编码。
由于 UTF - 8 的变字长,而对于大部分常用字符都是 1 或 2 个字节,所以对于 html、邮件的传输多用 UTF-8 进行编码后传输。
探索四
UTF - 8 有什么缺点吗?
对于一个字符串abc天气不错,如果我们知道它的总共大小是 19 字节,但是我们很难算出它有多少个字符。因为有的字符是 1 个字节,有的是 2 个字节,有的是 3 个。所以为了知道字符数,我们还需要遍历一遍所有字节,从而确定有多少个字符。此外如果我们想取第 3 个字符,我们还是得从第 0 个字节开始遍历,因为我们不知道每个字符有多少字节。
如果每个字符都用固定长度编码就好了,这不又回到 UTF - 32 了吗?不不不,我们折中一下。
对于 Unicode 字符集,基本平面是我们常用的一些字符,用两个字节就可以编码。所以对于亮字的话,码点值是0x4eae,那么我们内部就用 0x4eae 去存。而 ASCII 码只需要一个字节,那么我们把通过高位补零扩充至两个字节去存。例如A的码点值是 65,16 进制对应 0x41,用 U+41 表示。那么内部的话就用 0x0041 去存。
那么基本面以外的字符呢?比如𫠂这个字就属于基本面以外,它的 Unicode 码点值是 178178,也就是 0x2b802 ,显然用两个字节是存不下的,那怎么办呢?
用四个字节存呗,像 UTF - 32 那样直接存码点值,然后高位补零吗?显然不行了,因为第一平面我们是用的两个字节,如果第一平面外的直接用四个字节去存码点值的话,可能会导致前两个字节和基本面的两个字节重复,导致我们无法区分当前字符是两个字节还是四个字节。
UTF - 8 中,我们根据二进制开头的 1 的个数来表示当前字符是几个字节。这里的话,幸运的是在第一平面 U+D800..U+DFFF 的值不对应于任何字符。所以我们可以根据一些算法,把码点值转换为 4 个字节,前两个字节就用 U+D800..U+DFFF 中的值,这样如果前两个字节是 U+D800..U+DFFF 范围内的数,那就意味着该字符是 4 个字节编码的。否则就是两个字节。
这就是 UTF - 16 的编码方式了(具体的算法大家可以网上找一下),相对于 UTF - 8 的优势就是固定字节数,大部分字符都是两个字节。所以如果对于一个字符串abc天气不错如果采用 UTF - 16 编码,我们知道了它的总大小是 14 字节,那么字符数就很好知道了,它的大小除以 2 就是它的字符数了。而取第 4 个字符,如果知道了字符串开头的地址,也只需要加 2 * 4 就可以了(下标从 0 开始)。对于字符串的切割合并也都很好操作了。
所以对于一些语言 java,javascript 里的字符串也都用了 UTF - 16 编码。所以回到最开始的问题。
那么就取决于这些字符是不是在第一平面内了,如果是的话,那么结果就会就是 2 1 1。遗憾的是 “𫠂” 并不在基本平面,所以它内部是用四个字节编码,而 js 为了方便简单,它简单粗暴的认为两个字节就是一个字符,所以输出的就是 2 了。
此外关于,Unicdoe 所有的字符的码点值可以在 这个 网站找到。
实验验证
接下来说一下文件的存储。
我们打开一个 .txt,看到很多文字、符号,而内部其实也是用 0、1 存储的。既然要存储,就需要把 Unicode 的码点值进行编码。
如果是 UTF - 8 编码,那么一个码点值会生成 1 个或多个字节,然后把这些字节按顺序存就可以了。
如果是 UTF - 16 编码呢?
我们知道一个 Unicode 的码点值会对应一个数字,对于基本平面的字符,我们直接把这个数字存到内存中。那么问题来了,我们知道亮的码点值是 20142,换成 16 进制就是 0x4eae,内存中是按字节进行编址的。所以我们是先存4e呢?还是ae?先存4e吧,这样就符合我们人类阅读顺序,先读4e,所以先存4e呗。所以在内存中就是下边的样子。
1 | 内存地址 内存值 |
那么问题又来了,计算机处理的话先读取的是低地址,也就是4e,而4e对应数字0x4eae的高位(如果是 10 进制,个十百千,千就叫做高位)。有时候我们希望从低位读(也就是十进制中的个位)数字,所以我们希望这样去存。
1 | 内存地址 内存值 |
这就是多个字节存储的时候的字节序问题,把数字的高位存到低地址,低位存到高地址,叫做大端序(big endian),存储顺序符合我们人类习惯。反之就叫小端序(little endian)。
如果把亮字存到一个 .txt 中。
如果用 UTF-8 编码,那么前边算过的,就是e4 ba ae。
如果用 UTF-16 编码,大端序的话就是4eae。
如果用 UTF-16 编码,小端序的话就是ae4e。
我们可以验证一下,可以用 notepad++,安装一个 HEXEditor 插件即可。或者其他的可以查看内部编码的也行。
写一个亮到 text.txt
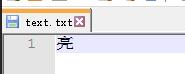
以 UTF - 8 编码。
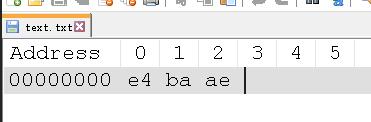
如果用 UTF - 16 编码,大端序
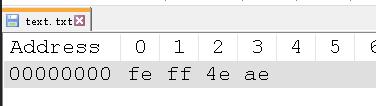
如果用 UTF - 16 编码,小端序

可以看到 UTF - 16 编码的时候,除了本身的字节,最开头还多了两个字节,ff和fe。原因很直接了,就是为了区分大端序和小端序。feff代表大端序,fffe代表小端序。
feff和fffe也叫做 BOM,它可以区分不同编码。我们也听过 UTF - 8 无 BOM 或者 UTF - 8 BOM。UTF - 8 的 BOM 是 EF BB BF,windows 记事本编写的 .txt ,如果以 UTF - 8 编码保存,它默认就是有 BOM 的,所以如果看他的内存存储就是下边的样子。

而 UTF - 8 并不存在字节序的问题,因为它的最小编码单位就是字节,而 UTF - 16 编码最小单位是两个字节,所以有字节序的问题,从而加了 BOM 来区分是大端序还是小端序。但是 UTF - 8 并不需要区分大端序还是小端序,所以可以不需要 BOM。如果加了 BOM,对于一些读取操作,它可能会把读取到的 BOM 认为是字符,从而造成一些错误。所以我们保存 UTF - 8 编码的文件时,最好选择无 BOM。
我们也可以在浏览器的控制台上直接验证,因为 js 允许我们直接给字符串赋 Unicode 的码点值。格式是 \u 加上 16 进制的码点值即可。对于超过 2 个字节的码点值,用大括号括起来。

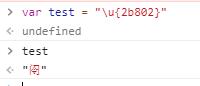
我们所熟知的 emoji 表情其实在 Unicode 字符集上也有对应的码点值。
比如最常用的笑哭脸的码点值是 U+1F602,当然 Unicode 只规定了码点值,并没有规定怎么实现,不同平台对于笑哭的表情展现也是不一样的。
同样我们也可以在浏览器上进行验证。

更多好玩
知道了上边的编码原则,我们就可以做些有趣的事情了,还记得「神奇字体」小程序吗?可以生成不同样式的字体,在微信、知乎发送。

𝙄 𝙡𝙤𝙫𝙚 𝙮𝙤𝙪 𝙩𝙝𝙧𝙚𝙚 𝙩𝙝𝙤𝙪𝙨𝙖𝙣𝙙
其实上边的每一个字母并不是对应 ASCII 码值,而是对应基本平面外的 Unicode 码点值。所以我们如果输出上边的 I 字母,”𝙄”.length,输出的就是 2,因为它是基本平面外的字符,用了 4 个字节编码。
大家可以回顾下,我之前写的探索过程,就会明白「神奇字体」的原理了。
此外,Unicode 还有一些组合字符、控制字符,实现不同字符的组合,比如删除线、下划线和字符的组合,实现字符的逆序输出等等,大家可以自己去探索下,蛮有意思的。
结束
以上就是字符串编码的全部了,这里只介绍了 ASCII,Unicode,UTF 系列,其他的编码方式还有 GBK,GB2312,Big5,ISO 8859-6 等等,这块内容真的是太多太多了,大家感兴趣的话可以自己再去找找资料,上边我总结的如果发现问题可以及时和我反馈,感谢。
