Neruron 美 [ˈnʊrɑn] : 神经元
activation 美 [ˌæktɪ’veɪʃn] : 活化,激活
feedforward 美 [‘fɪd’fɔwəd] : 前馈
backpropagation 美 [bækprɒpə’ɡeɪʃn] : 反向传播
本文是对李宏毅教授课程的笔记加上自己的理解重新组织,如有错误,感谢指出。
视频及 PPT 原教程:https://pan.baidu.com/s/1dAFnki 密码:5rsd
还没有看过前几篇机器学习理论的童鞋,推荐先把前几篇看完。
这里接着上篇的 Logistic Regression 来讲。
Limitation of Logistic Regression
看这样一个二元分类问题,假设我们有四个数据。

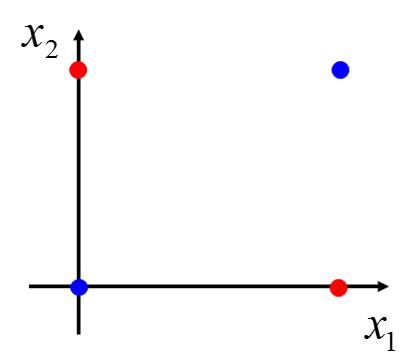
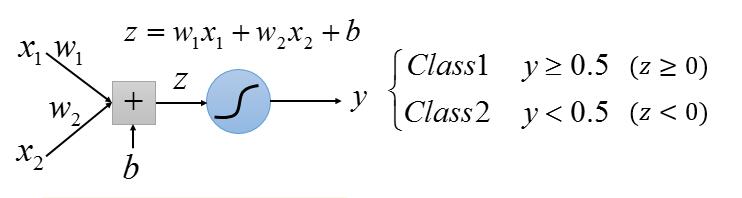
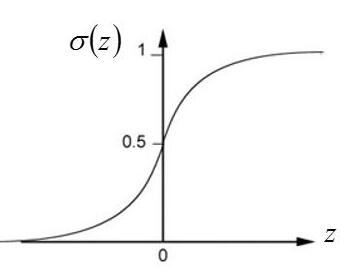
y ≥ 0.5 相当于 z ≥ 0 ; y < 0.5 相等于 z < 0 ; 而 z 相当于一条直线。所以 LR 的任务就是找一条直线,把两组数据分到直线的两侧。
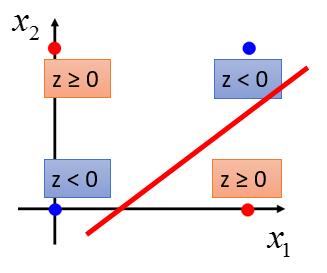
很明显,这是无法做到的。所以此时 LR 是无能为力的,我们怎么改进呢 ?
做 Feature transformation ,举个例子。
我们把 x1 变成 x1 到  的距离
的距离
x2 变成 x2 到 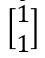 的距离
的距离
这样就改变了原始数据的分布,我们就可以找到一条直线分隔 class1 和 class2 ,从而实现我们的分类任务。
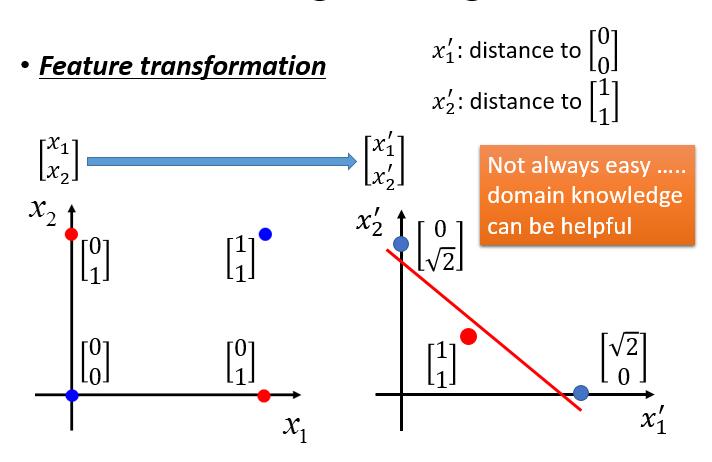
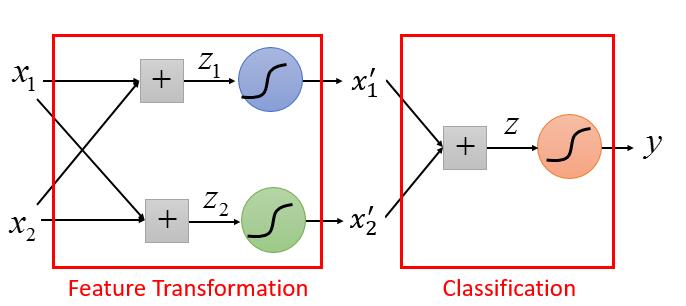
我们可不可以用几个 LR 连接起来解决呢?
带进几个具体的数值看一下。

然后把每个数据代入,求出新的 x1 ,x2 如下:
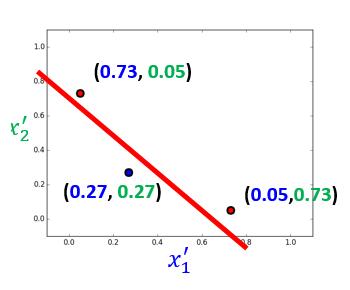
是的,达到了我们的目标!
是的这就是深度学习!!!!每一个 LR 我们叫它 Neruron ( 神经元)。我们再看下它的结构
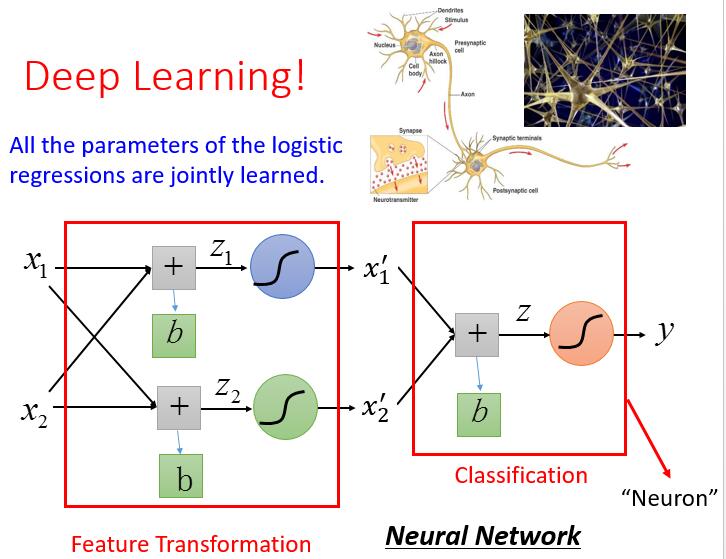
我们依旧举个例子吧,很简单,数字的识别吧。

当然,我们会先对它进行一些处理,去噪,二值化等,可以看下这里,让他变成只有黑白两种颜色。这样对于每个像素点就只有两个取值了。

每个像素点,我们都当做一维,这样我们每个数据就是这样

Model

深度学习的 Model 不像之前可以有一个固定的式子,它中间的神经元可以随便连接,不同的连接就是一个新的 Model 。可以尝试不同的连接,从而找一个可以满足自己预期的模型。最常见的有下边一种Fully Connect Feedforward Network (前馈全连接神经网络) 。
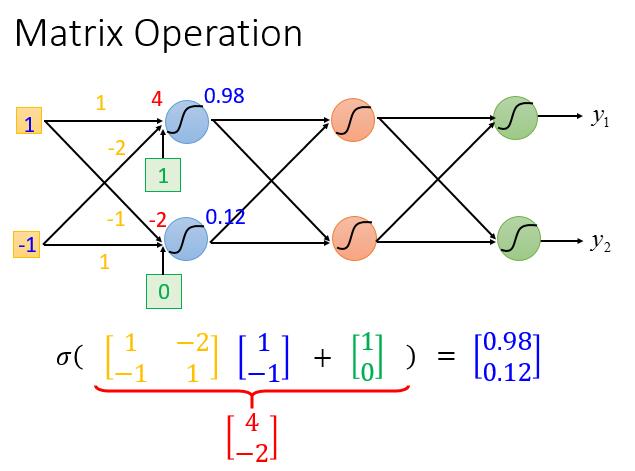
二维的图
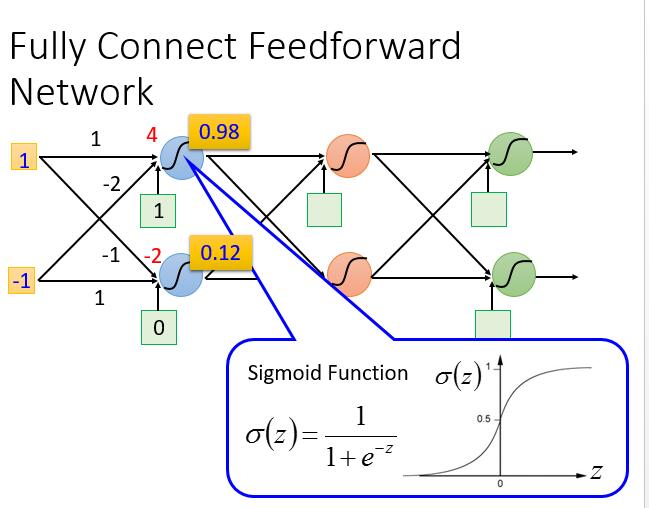
1 输入后到达第一个神经元会输出 0.98
-1 输入后到达第一个神经元会输出 0.12
我们的 S 形函数这里有了新的称谓,activation function ( 激励函数 ),当然它也可以不同S 形函数而换成别的函数,以后会讲到。
一般的形式:

输入 n 维的 x ,输出 m 维的 y ,每一维度代表属于该类的概率。
所以输出之前一般做一次 Softmax 。Softmax 是啥子嘞?中文翻译过来叫归一化指数函数 ,很形象,把每个值取 e 的幂次,然后归一一下。
假设我们有一个数组 V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是
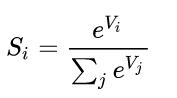
Goodness of Function
我们继续寻找它的 Loss Function !
我们先看一个数据的 loss ,例如是识别数字 1 。
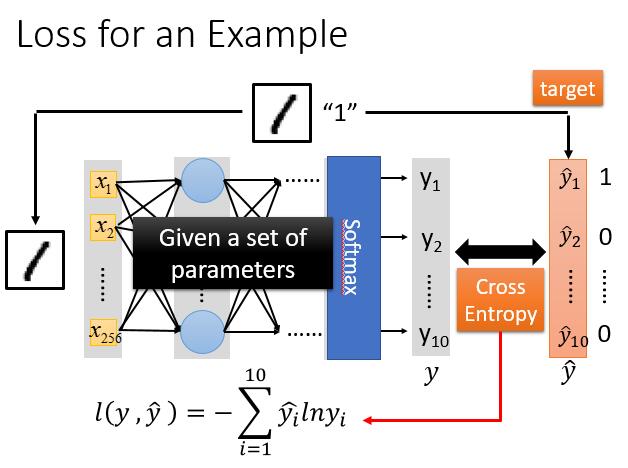
是的,我们把 Model 求出的 y 与 $\hat{y}$ 向上篇文章一样做 Cross Entropy ( ( 交叉熵 ) ,忘记的话可以再看一下上篇 。
有了一个数据的 loss ,我们要做的就是把所有数据的 loss 求和。
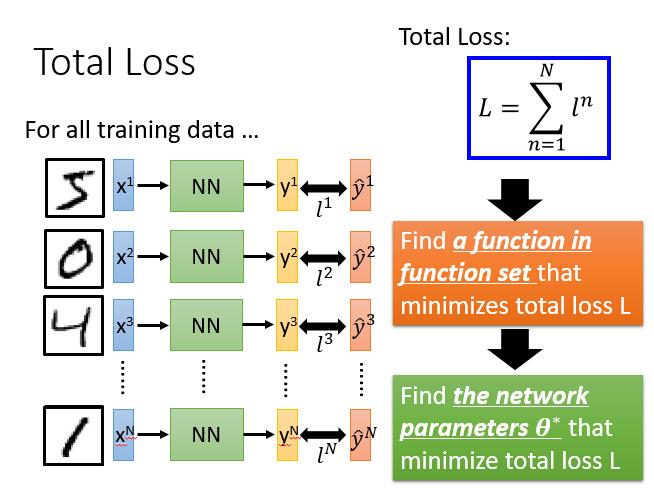
Best Function
我们得到了 Loss Function ,接下来就是求偏导,然后进行梯度下降。

是的你没有看错,高大上的深度学习依旧用的梯度下降,就算是 AlphaGo ,意不意外?惊不惊喜?
咦?偏导的公式为什么这次没给推导呀?
你知道 L 长这个样子

可是你知道 y 写出是什么样子吗?
每经过一个神经元,其实就是矩阵相乘
我们的 y 函数就是这样
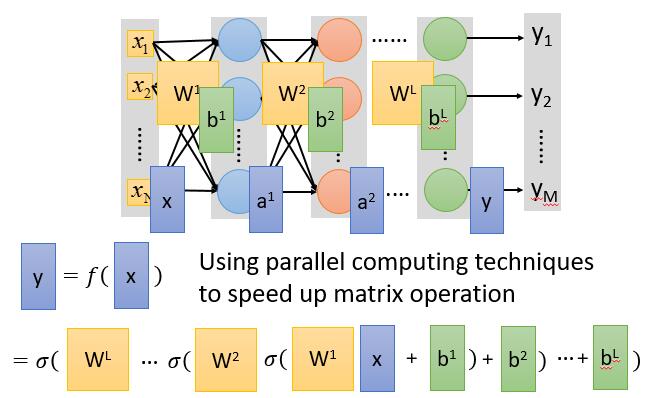
S 形函数一层套了一层,用笔去算偏导大概会疯掉。好在一些平台已经利用 Backpropagation ( 反向传播算法 ) 实现了梯度下降,我们直接去用就好了。

Backpropagation 以后我们再讲。
好了,上边就是深度学习 Deep learning 的基本理论了!!!!!!!!!!!!!!
应用
一图胜千言
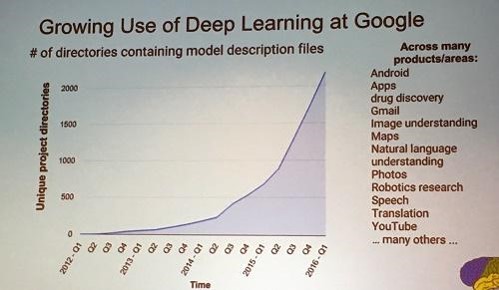
谷歌中用到了深度学习技术的项目数目,现在是真的火呀!
