背景
简单,即验证码简单,仅有数字,没有太大的干扰,每个数字都有固定的样子
还有就是识别的算法简单,可以说没有算法,主要是识别验证码的整个思想过程
环境
- python 2.7
- 我使用的是 windows 10系统
- python 的图片处理库 PIL
- python 的 requests 库,一个很方便的处理 HTTP 的库,这里仅仅是为了得到验证码图片
使用 pip 命令便可安装所需要的库,如果没有 pip 建议去安装下,python 的一个包管理工具,安装第三方包很方便1
2pip install Pillow //安装 PIL
pip install requests //安装 requests
取得验证码样本
分析网站的 html ,得到验证码地址,若是谷歌浏览器,右键审查元素即可看到
验证码地址是我们学校的,所以该地址只有用内网才可访问
这里提供些样本 百度云链接 密码:hj8t1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#!/usr/bin/python
#coding=utf-8
import requests
from PIL import Image
#下载
s = requests.session()
captcha_url='http://card.cug.edu.cn/Login/GetValidateCode?time=1498660044478' #验证码地址
for i in range(0,20): #得到 20 张验证码
captcha = s.get(captcha_url) # get 请求得到验证码
file='G:\\newcard\\Num\\'+str(i)+'.jpg' #写入本地文件
f = open(file, 'wb')
for line in captcha.iter_content():
f.write(line)
f.close()
然后就有了好多图片,可以先观察下
这些图片看起来似乎对数字进行了变形,但仔细观察无非每个数字有两个字体,一个居中,一个下沉
二值化并且去噪
转为灰度图
所谓灰度图就是有 0 ~ 255 共 256 种不同灰度的颜色
RGB 的颜色图转为灰度图其实有个公式 Gray = R*0.299 + G*0.587 + B*0.114,但我们直接用 Python 提供的函数即可1
2
3
4for num in range(0,20):
file='G:\\newcard\\Num\\'+str(num)+'.jpg'
im = Image.open(file)
im = im.convert('L') # 转为灰度图

可以看到有许多噪点,就是点啊点啊点,还有线啊线啊线,下边的目的是让他变得干净点
二值化去噪
我们下载的图片是有颜色的,所以要将图片二值化,也就是变成黑白图,而且是只有两种颜色的黑白图,0 黑色,255白色,所以叫二值化。
而去噪,我们只需要选定一个阙值,这个阙值的确定,试试就出来了,更科学的方法是看图片的直方图,看看灰度的分布,可以更快的得到阙值,反正最终目的是得到的图片清晰无噪音,不管黑猫白猫,抓住老鼠就是好猫,所以我是试出来的。直接了当,小于这个阙值,把值变为 0(黑),否则变 255 (白),如果效果不理想,可以更细致的划分范围1
2
3
4
5
6
7
8
9
10
11
12
13for num in range(0,20):
file='G:\\newcard\\Num\\'+str(num)+'.jpg'
im = Image.open(file)
im = im.convert('L') #变为灰度图
pixdata = im.load() #加载所有像素点
w, h = im.size #得到高和宽
for y in range(h):
for x in range(w):
if pixdata[x, y] < 190: #小于变 0
pixdata[x, y] = 0
else: #否则变 255
pixdata[x, y] = 255
im.save("G:\\newcard\\two\\"+str(num)+'.jpg', "GIF")
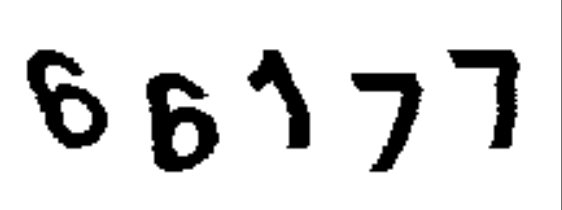
切割
这步没的说,就是为了取得每个数字的样本,0 ~ 9,每个的两种字体
下边 代码 x ,y 的确定 就是给个初始值,然后一个循环,一个矩形一个矩形的切,在纸上画一画,确定一个大体范围,具体的值就得一次一次看效果,一次一次微调了,最终目的是把一个数字切下来,最好是刚刚把数字包裹,但由于这个验证码一个是居中字体,一个是下沉字体,所以切出来要么下边留空,要么上边留空1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21nume=0
for num in range(0,20):
file='G:\\newcard\\Num\\'+str(num)+'.jpg'
im = Image.open(file)
im = im.convert('L') #变为灰度图
pixdata = im.load() #加载所有像素点
w, h = im.size #得到高和宽
for y in range(h):
for x in range(w):
if pixdata[x, y] < 190: #小于变 0
pixdata[x, y] = 0
else: #否则变 255
pixdata[x, y] = 255
im.save("G:\\newcard\\two\\"+str(num)+'.jpg', "GIF")
for i in range(0,5):
x = 8+i*42 #这里的数字参数需要自己
y = 19 #根据验证码图片的像素进行
temp = im.crop((x, y, x+42, y+49))
temp.save("G:\\newcard\\Temp\\%d.gif" % nume)
nume=nume+1

然后将 0 ~ 9 挑出来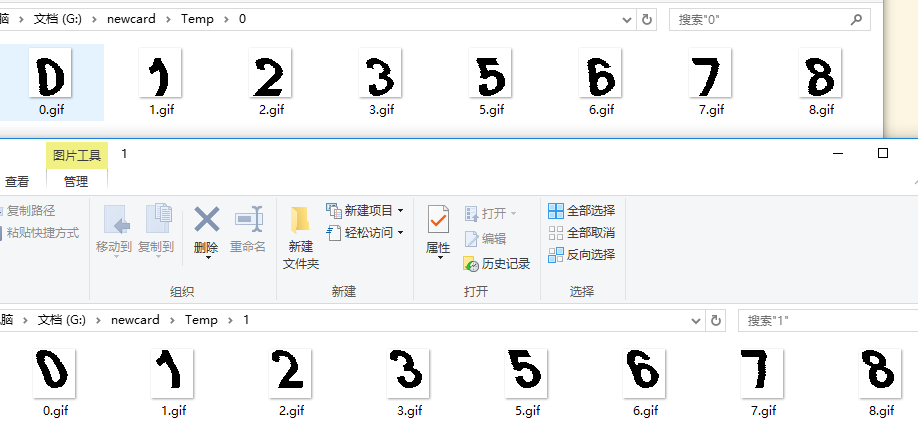
神奇的是这个网站的验证码里没有 4 和 9 ,不抓不知道,一抓吓一跳
识别验证码
实时的取得当前的验证码,然后将其切割成一个一个,然后与上边步骤取得的 0 ~ 9 18个 数字依次比对,这里用到的算法就是最容易想到的,就是对应的像素点依次比较,相等变量值减一,然后从这些里找最小的,也就是匹配最多的那个。在测试中发现,当然只针对这个网站的验证码,先和下沉的9个数字比较,然后发现好几个数字都错误识别为0,然后再如果等于 0,就再用居中的数字就行比较,选出最佳,此时识别率最高。
1 | #!/usr/bin/python |

增加识别率到 100%
经过上边的步骤你会发现,总会把某些数字错认为固定的数字,电脑还真是固执。而不同的网站,错认的还不一样,所以为了达到更高的识别率,这一步是最耗时的了,而且还真的是只能靠运气,不停的改数字,不停的试。它的思想就是,之前我们比较的是一个图片的全部像素,在 min=re(‘1’,temp,42,49) 函数中传入切割图片的大小,42*49,现在我们可以改变这个值,将切割图片的部分像素和样本的对应像素进行比较,然后选最佳。
举个例子,就是它把 下沉的 3,居中的 2,下沉的 0 都认成 8,所以如果结果是 8,我们再对其进行判断,当然这又会引起本来认对的数字认错,这是写一些 if 语句进行纠正,就是如果本来是 3,然后此时认成了 5,我们再把值变回 3。然后再不停的试,也就是 改函数的最后两个参数,并且加 if 直到完全正确。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25if (min == 6):
t = re("1", temp, 42, 23)
if (t == 8 or t == 5):
min = 0
if(min==8):
t=re("1",temp,35,35)
min = t
if(t==5):
min=3
if(t==0):
min=8
if(t==6 ):
min=0
if(min==8):
t = re('0', temp, 30, 20)
if(t==7):
min=8
if(t==0):
min=0
if(min==0):
t = re('0', temp, 30, 20)
if(t==2 or t==6):
min=6
对结果不停的判断,不停的试,不同网站也不一样,理解其思想即可。
总结
基本思想就是,不管是样本还是要判断的验证码将其用同样的方式二值化 去噪 切割,得到验证码的所有样本,然后将切割的每个数字和样本利用某个算法进行比较,进行判断,得出结果。最后再利用某些算法,修正部分固定的一些错误。
